https://github.com/TencentCloudADP/youtu-agent
![[Uncaptioned image]](figs/logo.png) Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Abstract
Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose Youtu-Agent, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a Workflow mode for standard tasks and a Meta-Agent mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an Agent Practice module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an Agent RL module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47%) and GAIA (72.8%) using open-weight models. Our automated generation pipeline achieves over 81% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7% and +5.4% respectively. Moreover, our Agent RL training achieves 40% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35% and 21% on Maths and general/multi-hop QA benchmarks.
1 Introduction
As Large Language Models (LLMs) evolve towards general purpose agents, building systems that autonomously solve complex real-world tasks has become a central pursuit in AI research. However, the current landscape of agent development is hindered by two primary bottlenecks.
High Configuration Costs. Developing a robust agent remains a labor-intensive process. On one hand, practitioners must select appropriate tools and craft effective prompts, which require significant domain expertise and iterative refinement. On the other hand, implementing custom tools demands substantial engineering effort, including writing Python functions, integrating external APIs, and handling edge cases. This “craftsman” approach creates a high barrier to entry and limits the scalability of agent deployment.
Static Capabilities. Once deployed, most existing agents remain static and struggle to adapt to new environments. Improving their performance typically requires one of two approaches: (1) manual optimization of prompts or few-shot examples, which is costly and offers no guarantee of improvement; or (2) Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL), which face substantial challenges including data scarcity, high computational costs, and training instability issues such as “entropy explosion” in long-horizon tasks.
To overcome these challenges, we present Youtu-Agent, a comprehensive framework that bridges the gap between “automated construction” and “continuous optimization.” To address high configuration costs, Youtu-Agent adopts a layered, modular architecture that decouples Environment (execution context), Toolkits (atomic operations), and Agent (LLM-driven planning) into standardized components. This design enables a YAML-based structured configuration system that facilitates component reuse and serves as the foundation for automated generation. Building on this architecture, we provide two generation paradigms: the Workflow mode offers a deterministic pipeline for routine tasks, while the Meta-Agent mode deploys a higher-level architect agent to handle complex, dynamic requirements.
To address static capabilities, Youtu-Agent establishes a hybrid policy optimization system. For low-cost scenarios where manual prompt optimization proves unreliable, we introduce the Agent Practice module, which enables agents to accumulate experience and self-evolve during runtime. By performing parallel rollouts on dozens of samples and leveraging group relative experiential knowledge optimization, the agent builds a contextual memory that enhances future performance without gradient updates. For scenarios demanding significant and lasting performance improvement, the Agent RL module integrates with existing RL training frameworks and bridging protocols to provide an end-to-end reinforcement learning recipe. To ensure both stability and scalability during RL, our module tackles the concurrency bottleneck and entropy explosion/collapsing challenges respectively from the infrastructure and algorithm implementations.
Our contributions are as follows:
-
•
Framework Efficiency. Built entirely on open-source models and tools, Youtu-Agent achieves 71.47% pass@1 on WebWalkerQA and 72.8% pass@1 on GAIA (text-only subset), establishing a strong open-source baseline and validating the framework’s general applicability.
-
•
Automated Agent Generation. Through our two-paradigm generation mechanism, we demonstrate the potential of LLMs to automatically generate tools and agent configurations, significantly reducing the burden of manual configuration. The automated tool synthesis achieves over 81% success rate.
-
•
Continuous Experience Learning. Through the Agent Practice module, we enable low-cost continuous evolution of agents via in-context experience accumulation. This approach yields +2.7% and +5.4% absolute improvements for DeepSeek-V3.1-Terminus on AIME 2024 and AIME 2025, respectively.
-
•
Scalable and Stable Agent RL. Through the Agent RL module, we address the scalability and stability challenges in large-scale reinforcement learning training. Our optimizations achieve a 40% speedup in training iteration time and improve Qwen2.5-7B accuracy on AIME 2024 from 10% to 45%, demonstrating the framework’s potential for building evolvable agents.
2 Youtu-Agent Framework
Youtu-Agent is designed with modularity and automation at its core. The framework comprises three hierarchical layers—Environment, Tools, and Agent—supported by a structured configuration system that enables both manual flexibility and automated synthesis. Beyond the execution architecture, the framework provides components for continuous optimization: the Agent Practice module enables low-cost experience-based improvement, while the Agent RL module supports end-to-end reinforcement learning. In this section, we describe each component in detail.
2.1 System Architecture
2.1.1 Execution Framework
The agent execution architecture is organized into three hierarchical layers. This layered design decouples concerns and enables flexible reuse of components across different agents.
Environment Layer. The Environment Layer provides the foundational execution context and low-level capabilities. It serves as the substrate upon which tools operate, exposing both state information (such as current page content or filesystem status) and primitive interfaces. Typical backends include browser instances for web navigation (e.g., Playwright-based browser environments), operating system shells for command execution, and sandboxed code execution environments (e.g., E2B). The environment abstraction allows the same tools and agents to operate across different backends with minimal modification.
Tools Layer. The Tools Layer encapsulates atomic and composite operations behind stable interfaces that the agent can invoke. Tools fall into three categories: (1) environment-related tools that wrap low-level environment APIs (e.g., clicking a DOM element, running a bash command, taking screenshots), (2) environment-independent utilities that perform standalone computations (e.g., mathematical operations, text processing, date/time handling), and (3) MCP tools that integrate external Model Context Protocol services for extended capabilities. This categorization allows tools to be composed, shared, and reused across different agents and environments.
Agent Layer. The Agent Layer houses the LLM-driven planner/executor that orchestrates task completion. The agent operates through a perceive–reason–act loop: it perceives environment state provided by the Environment Layer, reasons about the next steps using LLM capabilities, and selects appropriate tools to act. To handle long-horizon interactions that can overwhelm the model’s context window, we incorporate a Context Manager module within this layer. The Context Manager maintains a compact working context by pruning stale or redundant information while preserving essential state. For example, in browser-based tasks, it removes obsolete HTML from prior navigation steps to control token cost without losing task-critical history.
2.1.2 Configuration System
A distinguishing feature of Youtu-Agent is its YAML-based structured configuration system. All components—environment specification, tool selection, agent instructions, and context management settings—are declared via human-readable YAML files. This standardized format serves dual purposes: it facilitates manual composition and sharing of agent configurations, and it provides the target schema for our automated generation mechanisms (Section 2.2). An example configuration is shown below:
This configuration specifies an agent with E2B sandbox environment, the default context manager, and two toolkits for web search and Python code execution. The declarative nature of YAML configurations enables rapid prototyping and systematic management of agent variants.
2.1.3 Continuous Optimization Components
Beyond execution, the framework emphasizes continuous agent improvement. Three supporting components enable this capability:
-
•
Eval: Evaluates agent performance on predefined benchmarks, providing standardized metrics for comparison and iteration.
-
•
Agent Practice: Enables low-cost experience accumulation on small datasets without parameter updates (Section 2.3).
-
•
Agent RL: Supports end-to-end reinforcement learning training for scenarios requiring peak performance through parameter optimization (Section 2.4).
These components transform Youtu-Agent from a static execution framework into an evolvable system capable of continuous self-improvement.
2.2 Automated Generation Mechanism
Building upon the structured configuration system, Youtu-Agent provides automated mechanisms for generating complete agent configurations from high-level task descriptions. We introduce two generation paradigms tailored to different complexity levels and use cases, as illustrated in Figure 1.
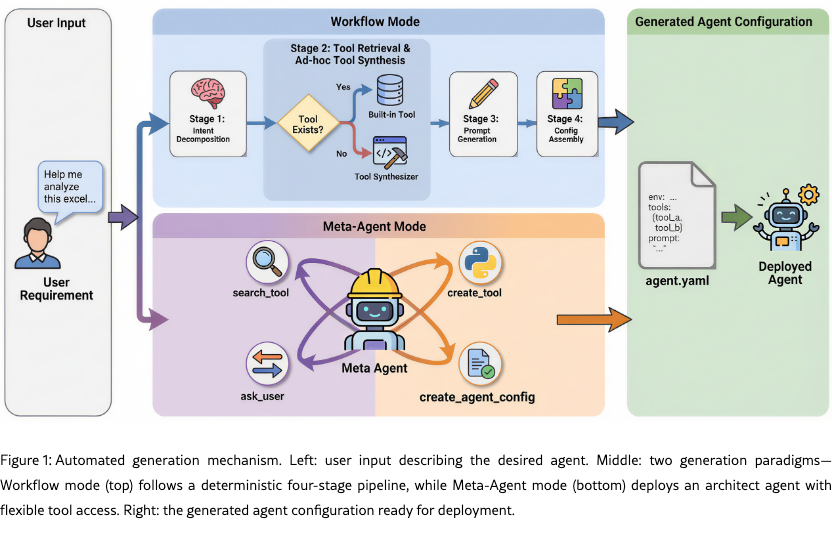
2.2.1 Workflow Mode
The Workflow mode follows a deterministic, four-stage pipeline suitable for well-defined, routine agent construction tasks:
Stage 1: Intent Clarification and Decomposition. The user’s high-level task description is analyzed and decomposed into specific technical requirements. This stage identifies core objectives, necessary capabilities, and potential environmental constraints, producing a structured specification for subsequent stages.
Stage 2: Tool Retrieval and Ad-hoc Tool Synthesis. Based on the clarified requirements, the system searches the existing toolkit library for relevant tools. If required tools are missing, the Ad-hoc Tool Synthesis module automatically generates new Python tool implementations, complete with function signatures, docstrings, and unit tests. This synthesis process leverages LLMs to produce executable code that integrates seamlessly with the framework’s tool interface.
Stage 3: Prompt Engineering. With the selected or synthesized tools identified, this stage generates optimized system instructions. The prompt engineering process considers task requirements, tool usage patterns, and desired agent behavior to produce effective instructions.
Stage 4: Configuration Assembly. The final stage compiles all components—environment specification, selected tools, generated prompts, and context management settings—into a complete YAML configuration file ready for deployment.
This workflow provides a standardized, reproducible pipeline for agent generation, enabling rapid development of agents for common task categories.
2.2.2 Meta-Agent Mode
For complex or ambiguous requirements that resist a fixed pipeline, the Meta-Agent mode deploys a higher-level Architect Agent that treats generation capabilities as callable tools. The meta-agent is equipped with: search_tool (retrieve existing tools from the library), create_tool (synthesize missing Python tools with signatures, docstrings, and unit tests), ask_user (gather missing constraints or preferences through multi-turn dialogue), and create_agent_config (assemble the final YAML configuration).
With these capabilities, the meta-agent can dynamically plan the generation process: it conducts multi-turn clarification with ask_user to elicit task scope and constraints, alternates between search_tool and create_tool depending on toolkit coverage, and finally integrates all components via create_agent_config.
2.3 Continuous Experience Learning
How can we adapt an agent to specific tasks without expensive parameter fine-tuning? Traditional approaches face significant limitations: manual prompt engineering is labor-intensive with no guarantee of improvement, while SFT or RL requires substantial data and computational resources. To address this, the Agent Practice module integrates Training-free Group Relative Policy Optimization (Training-free GRPO) [1], enabling low-cost agent improvement through in-context experience accumulation without any gradient updates.
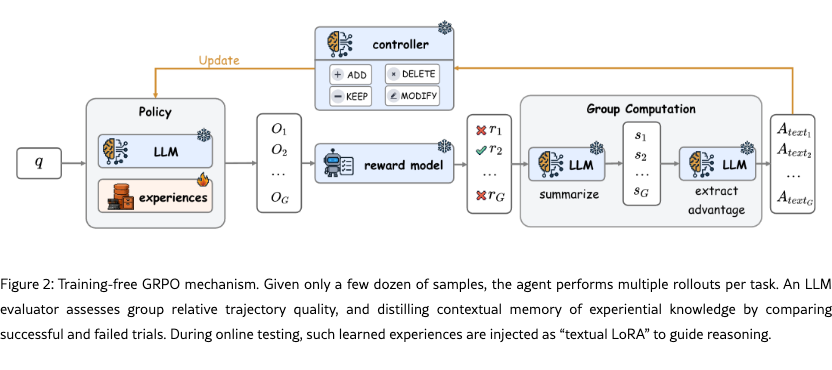
The core mechanism operates as follows: on a small training dataset (with or without ground truth), the agent performs multiple rollouts per task, generating diverse solution trajectories. Inspired by GRPO’s group relative optimization, an evaluator assesses the relative quality of trajectories for the same task. Rather than calculating a numerical advantage in vanilla GRPO, the LLM introspects on these diverse outputs and distill a semantic group advantage, i.e., a textual learning direction derived from contrasting successful and failed trials. Such advantage optimizes the existing experiential knowledge, serving as a refined policy for subsequent epochs. After completing practice, during online testing, these experiences are injected into the agent’s context, acting as a form of “textual LoRA” that guides reasoning without modifying model weights.
Compared with traditional learning approaches, the agent practice module requires no gradient computation, works with API-based models where fine-tuning is inaccessible, leverages small training sets effectively, and allows experiences to be accumulated continuously.
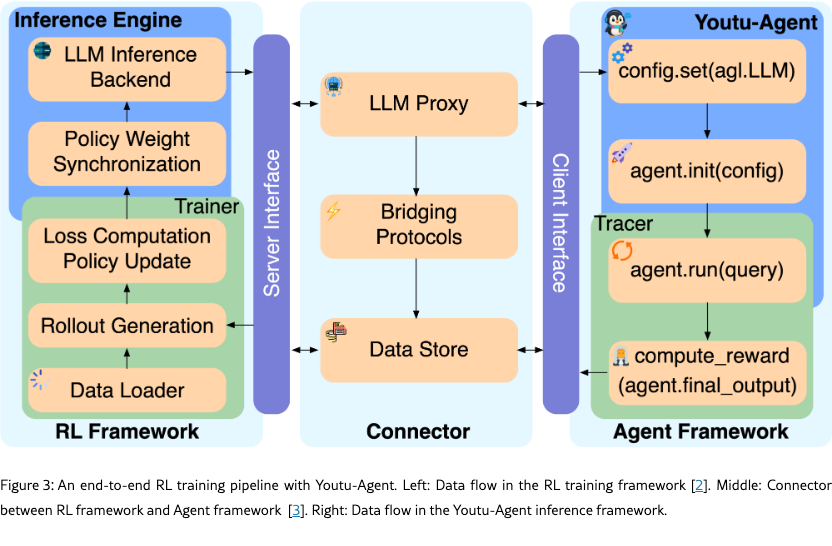
2.4 Agent RL Training
For applications requiring significant and lasting performance improvement, the Agent RL module provides a complete pipeline for end-to-end, production-grade reinforcement learning (see Figure 3). We implement custom agent logic within our framework for inference, and integrate with Agent-Lightning [3] as the connector between Youtu-Agent and modern RL framework such as VeRL [2] for distributed training. Such integration addresses two critical challenges that have historically limited agent RL: scalability to large distributed systems and stability over long-horizon tasks.
Scalability Solutions. Scaling agent RL presents unique challenges due to the complex, stateful nature of agent-environment interactions. We address these through: (1) RESTful API wrapping that encapsulates agent execution environments as standardized services, enabling seamless distribution and load balancing; (2) Ray-based concurrency for highly parallel rollout collection across distributed workers; and (3) layered timeout logic with hierarchical controls at tool, step, and episode levels to handle various potential timeout issues without fatal failures. Such infrastructure-level optimization enables stable scaling to 128 GPUs.
Stability Solutions. Long-horizon agent tasks exacerbate the “entropy explosion” problem where policies degenerate into repetitive or nonsensical actions. We mitigate this through: (1) filtering invalid and anomalous tool calls from training data to prevent learning degenerate patterns; (2) removing batch shuffling and reducing off-policy update iterations to prevent the policy from overfitting the outdated experience; and (3) correcting bias of advantage estimation in turn-level GRPO training. These techniques ensure stable training dynamics with consistent performance improvements across hundreds of training steps.
3 Experiments
We evaluate Youtu-Agent across four dimensions: general agent capabilities on standard benchmarks, effectiveness of automated generation mechanisms, low-cost improvement through the Agent Practice module, and scalable Agent RL training.
3.1 Benchmark Performance
To validate the effectiveness of our framework design and tool implementations, we evaluate Youtu-Agent on established agent benchmarks. Prioritizing accessibility and reproducibility, we build our agents entirely on open-source models—specifically the DeepSeek-V3 series—without relying on proprietary APIs such as Claude or GPT. We adopt a Plan-and-Execute paradigm, where a planner agent orchestrates task decomposition and scheduling while specialized executor agents handle subtasks.
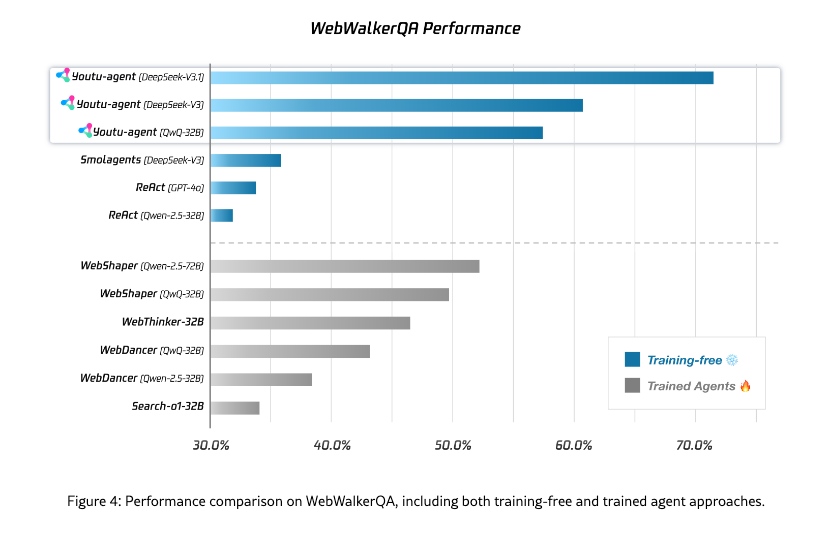
WebWalkerQA. This benchmark (680 questions) evaluates LLMs’ ability to perform multi-step, deep web navigation and question answering over real websites. Equipped with web search and crawling tools, Youtu-Agent achieves 71.47% pass@1 accuracy, as shown in Figure 4. This result demonstrates robust environment interaction and multi-step exploration capabilities.
GAIA (Text-only Subset). GAIA [4] (466 questions) tests real-world question answering requiring reasoning, multimodal understanding, web browsing, and tool-use proficiency. Since we use text-only models, we evaluate on the text-only subset. Beyond web tools, we provide document parsing and code execution capabilities to handle file attachments. Youtu-Agent achieves 72.8% pass@1 accuracy, demonstrating effective tool selection and deep reasoning abilities that validate our framework’s design for general-purpose agent applications.
These results establish Youtu-Agent as a competitive open-source baseline without requiring proprietary APIs or closed-source systems.
3.2 Automated Generation Effectiveness
We evaluate the practical utility of Youtu-Agent’s automated generation mechanisms through quantitative metrics and a qualitative case study.
3.2.1 Evaluation Framework
Given the absence of established benchmarks for automated agent generation, we construct AgentGen-80, a benchmark consisting of 80 diverse task descriptions ranging from simple information retrieval to complex multi-step automation. We assess generation quality across three dimensions:
-
•
Configuration Validity (CV): Whether the generated YAML configuration is structurally valid and semantically complete.
-
•
Tool Executability (TE): Whether synthesized tools compile and execute successfully with expected functionality.
-
•
Task Completion (TC): End-to-end effectiveness—whether the generated agent successfully completes the specified task.
3.2.2 Comparative Results
We compare the Workflow mode and Meta-Agent mode on AgentGen-80. Table 1 presents the results.

The Workflow mode achieves 100% configuration validity, demonstrating the robustness of its deterministic four-stage pipeline. The Meta-Agent mode achieves 98.75% validity—the occasional failures occur when the final create_agent_config tool call fails to produce well-formed output. For Tool Executability (TE), both modes use the same tool synthesis module, achieving 81.25% and 82.50% respectively with no significant difference. For Task Completion (TC), we manually test the generated agents through dialogue to verify expected behavior, yielding 65.00% and 68.75% completion rates. The Meta-Agent mode shows slightly better end-to-end effectiveness.
3.2.3 Case Study
We illustrate the Meta-Agent mode with a concrete example. For the user query “Summarize today’s trending papers on multi-agent system and download PDFs,” the Architect Agent first calls search_tool to search the existing library, finding the arxiv toolkit with paper download capabilities. Finding no existing tool for fetching daily paper updates, it calls create_tool to synthesize a new tool fetch_daily_papers. Finally, it calls create_agent_config to assemble the configuration file shown below:
Within the create_tool invocation, a subagent queries the web to retrieve related API documentation, then implements the tool in Python. The core implementation is shown below, and the synthesized tool is exposed via MCP (Model Context Protocol) to the generated agent, enabling seamless integration with the execution loop.
3.3 Agent Practice Module Results
As introduced in Section 2.3, the Agent Practice module integrates Training-free GRPO to enable low-cost agent improvement through experience accumulation without parameter updates. We validate its effectiveness on challenging mathematical reasoning benchmarks AIME 2024 and AIME 2025 [5], using Mean@32 for robust measurement.
Experimental Setup. Our evaluation is based on ReAct [6] with a code interpreter tool. During the learning stage, we randomly sample 100 problems from the DAPO-Math-17K [7] dataset and run 3 epochs with group size and temperature . For online testing, the temperature is set to .
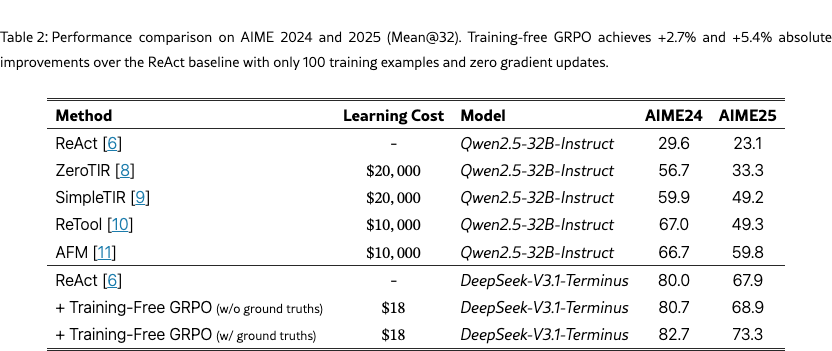
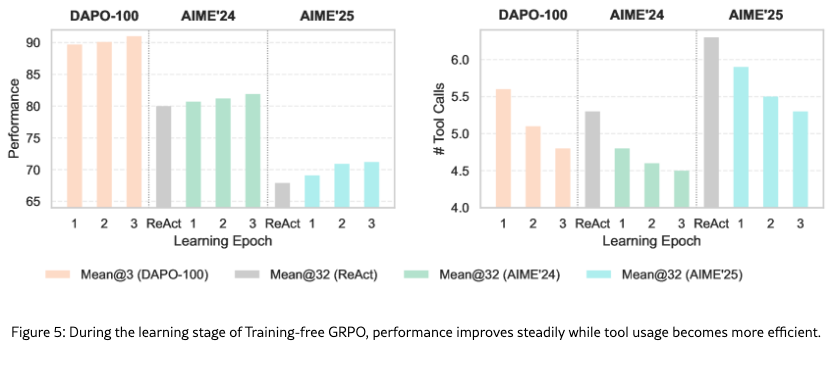
As shown in Table 2, when ground truths are available for the training samples, Training-free GRPO achieves +2.7% on AIME 2024 and +5.4% on AIME 2025 compared to ReAct, demonstrating the effectiveness of learned experiences. Notably, the variant without ground truths still achieves strong results, validating applicability to domains where labeled data is scarce. Compared to RL methods requiring 10,000+ training samples and approximately $10,000 for fine-tuning a 32B model, Training-free GRPO achieves better performance with only 100 samples and approximately $18 learning costs, offering a highly effective and accessible pathway for real-world applications. Furthermore, as shown in Figure 5, both learning and validation performance improve steadily across epochs, and the average number of tool calls is decreasing, which indicates that the agent learns more efficient problem-solving strategies.
3.4 Agent RL Training Results
As introduced in Section 2.4, our Agent RL module proposes modifications to both infrastructure and algorithm implementation of Agent-Lightning [3] to enable scalable and stable end-to-end RL training. The effectiveness of our optimization is confirmed through both training efficiency and stability on multiple benchmarks.
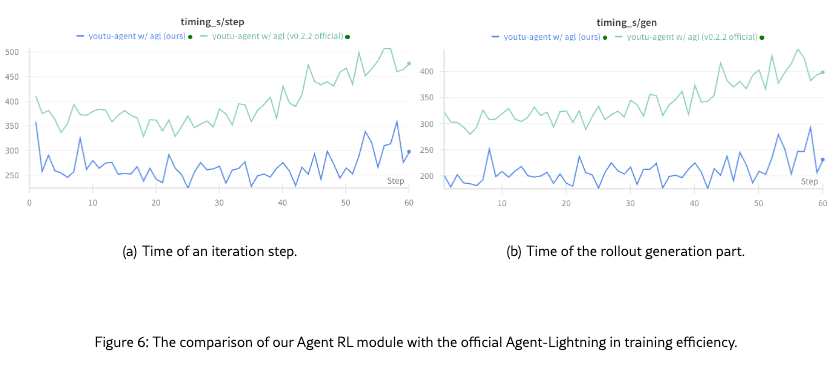
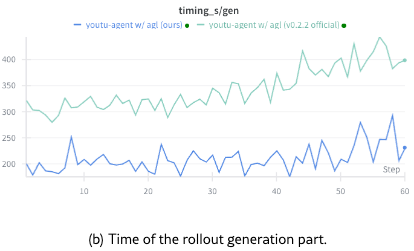
Efficiency. Compared with the Agent-Lightning (v0.2.2 official version), our infrastructure optimizations such as concurrency control, RESTful API wrapping, and hierarchical timeout logic reduce iteration time by approximately 40%, enabling efficient scaling to 128 GPUs without timeout issues (see Figure 6).
Effectiveness. To ensure fair comparison, we perform RL training of Qwen2.5-7B-Instruct on two typical tasks: 1) math/code for reasoning capabilities, and 2) search for information-seeking capabilities.
For the math/code task, we follow the experimental settings of ReTool [10] where a code interpreter (sandbox) is prepared as an external tool for assistance of solving mathematic problems. As shown in Figure 3, evaluation results confirm that the accuracy gains of 35% and 22% are respectively achieved on AIME24 and AIME25.
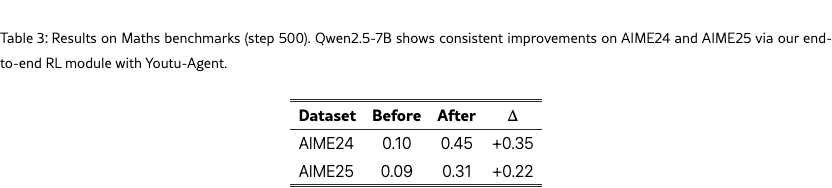
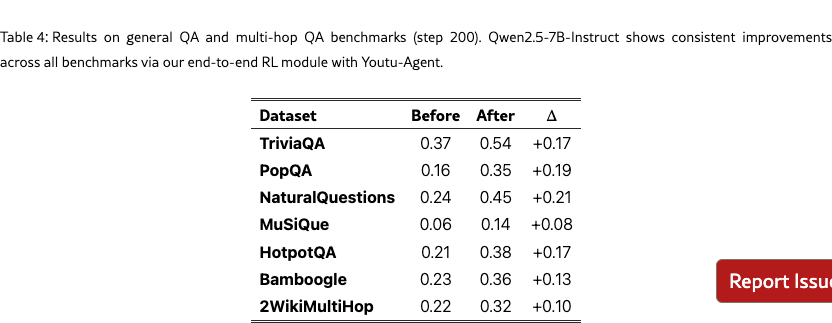
For the search task, we follow the experimental settings of SearchR1 [12] where a local wikipedia-2018 retrieval service (E5-HNSW64 embeddings) is prepared as an external tool for solving general QA and multi-hop QA problems. As shown in Table 4, consistent improvements are observed across all benchmarks with accuracy gains of 17%, 19%, 21%, 8%, 17%, 13%, and 10% respectively on TriviaQA, PopQA, NatureQuestions, MusiQue, HotpotQA, Bamboogle, and 2WikiMultiHop.
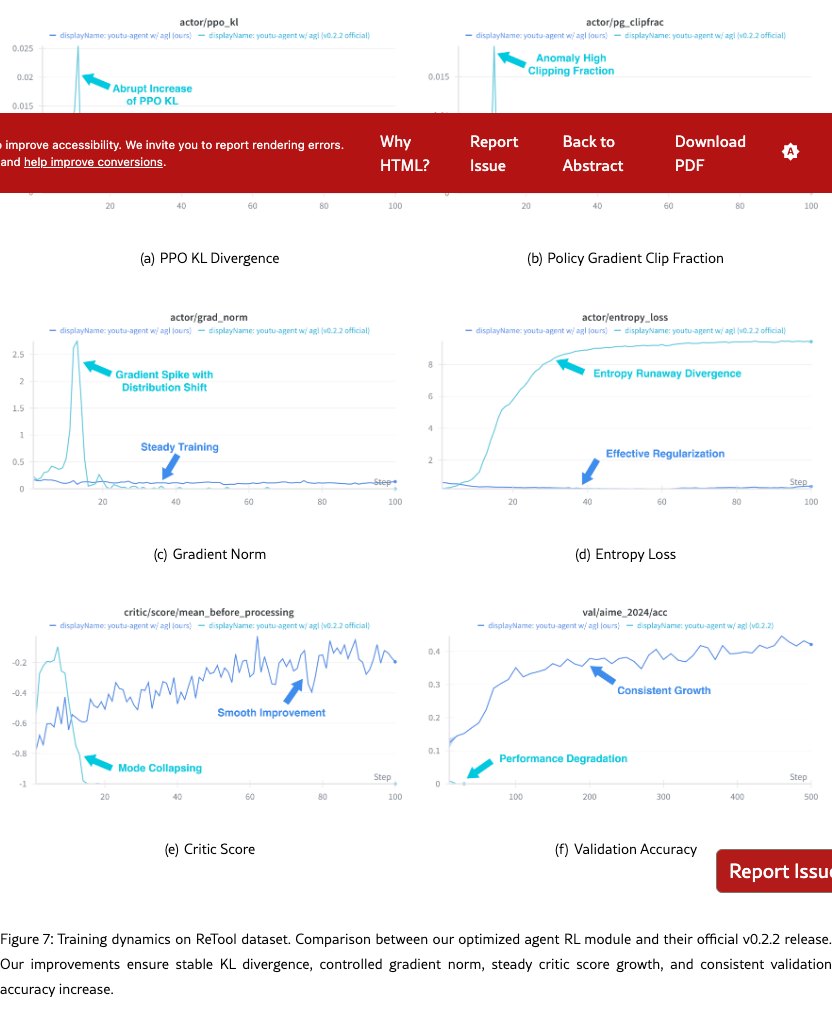
Training Dynamics. Figure 7 illustrates the training dynamics for comparison with the official Agent-Lightning release. After our improvements addressing “entropy explosion”, the actor’s KL divergence and gradient norm remain stable. It can be observed that critic score increases steadily, which is in line with the validation accuracy.
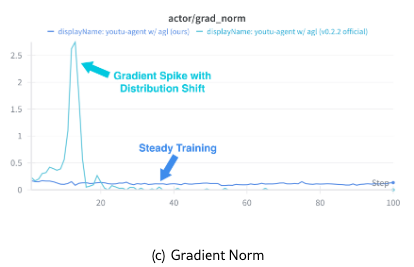
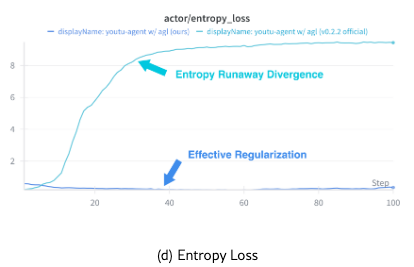
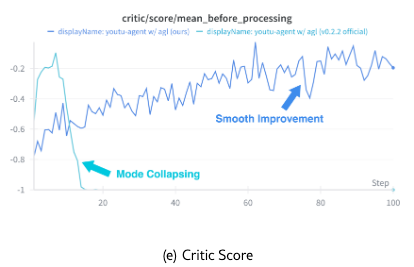
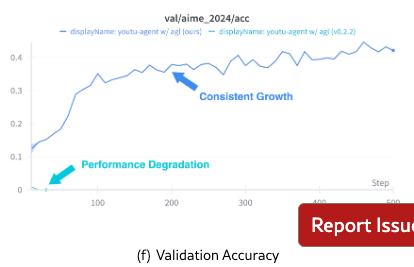
These experiments demonstrate that Youtu-Agent not only provides a robust execution framework but also supports effective model training for building continuously improving agents.
4 Related Work
4.1 Agent Frameworks
Recent years have seen a proliferation of agent frameworks. MetaGPT [13], AutoGen [14], and ChatDev [15] have popularized multi-agent collaboration, assigning static roles to LLMs to solve complex tasks. While effective, these frameworks often rely on predefined roles and heavy prompt tuning. Youtu-Agent advances this paradigm by automating the generation of agent configurations themselves, including executable tool code and optimized prompts, rather than just orchestrating static roles.
4.2 Automated Agent Design
Research into automated agent design, such as ADAS [16] and AutoAgents [17], has explored generating agents from high-level descriptions. Youtu-Agent distinguishes itself by not only generating the agent’s design but also synthesizing the necessary tool code (Python) and providing a unified pipeline that extends from automated generation to continuous optimization.
4.3 Agent Optimization and Learning
Optimizing agents typically involves either prompt optimization or parameter updates. Reflexion [18] and ReAct [6] use verbal reinforcement and reasoning traces to improve performance without training. On the training side, Toolformer [19] and Gorilla [20] focus on fine-tuning for tool use. Youtu-Agent integrates both approaches: the Practice module enables low-cost, inference-time improvement through experience accumulation, and the Agent RL module provides a full-scale RL pipeline for end-to-end parameter optimization, addressing the stability issues often encountered in PPO/RLHF for agents.
5 Conclusion
We presented Youtu-Agent, a modular framework for automatic agent generation and continuous improvement. The framework addresses two fundamental challenges in LLM-based agents: high configuration costs and static capabilities.
Key Contributions. (1) A modular, YAML-based architecture that decouples environments, tools, and context management for flexible agent composition. (2) Dual-paradigm automated generation through workflow pipelines and meta-agent interaction. (3) An Agent Practice module for low-cost optimization using small datasets without gradient updates. (4) An Agent RL module for scalable and stable end-to-end reinforcement learning training.
Empirical Results. Youtu-Agent achieves 71.47% on WebWalkerQA and 72.8% on GAIA using only open-source models. Our automated generation achieves over 81% tool executability and up to 68.75% task completion. The Practice module improves AIME performance by +4.8%/+7.0% with only 100 samples and $18 cost. The Agent RL module enables 40% speedup and stable 128-GPU scaling, improving Qwen2.5-7B from 10% to 45% accuracy on AIME 2024.
Future Directions. We plan to expand the framework with more environment integrations, enhanced multi-agent collaboration capabilities, and more sophisticated experience accumulation strategies.
6 Application
To make youtu-agent more accessible to end users, we present Tip, an on-device, multimodal desktop assistant that keeps data local, integrates Youtu-Agent, and can directly drive a GUI agent. Key functions include:
-
•
Youtu-Agent inside: load and run existing Youtu-Agent configs to handle bash commands, file management or more complex tasks within a unified UI.
-
•
Proactive intent and context completion: automatically capture relevant screen/text context and surface intents, no manual copy/paste or typing needed.
-
•
GUI Agent with skills: automate desktop actions end to end, then save and replay “GUI skills” as reusable workflows for continual improvement.
-
•
On-device model support: run local models to keep data private and secure.
Tip let users ask at their fingertip without further tiresome operation while achieving complex goal smoothly, locally and safely. We aim for this project to catalyze the development and practical adoption of the Agent technology community in future.

Contributions
Authors Yuchen Shi1* Yuzheng Cai1,2*† Siqi Cai1* Zihan Xu1* Lichao Chen1,3† Yulei Qin1 Zhijian Zhou1,2 Xiang Fei1 Chaofan Qiu1 Xiaoyu Tan1 Gang Li1 Zongyi Li1 Haojia Lin1 Guocan Cai1 Yong Mao1 Yunsheng Wu1 Ke Li1 Xing Sun1
Affiliations 1Tencent Youtu Lab 2Fudan University 3Xiamen University
* Equal Contribution †Work during Internship at Tencent Project Lead Correspondence: winfredsun@tencent.com
Acknowledgments
We thank the teams behind Agent-Lightning for their open-source contributions that enabled our scalable RL training experiments.
References
- Cai et al. [2025] Yuzheng Cai, Siqi Cai, Yuchen Shi, Zihan Xu, Lichao Chen, Yulei Qin, Xiaoyu Tan, Gang Li, Zongyi Li, Haojia Lin, et al. Training-free group relative policy optimization. arXiv preprint arXiv:2510.08191, 2025.
- Sheng et al. [2025] Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025.
- Luo et al. [2025] Xufang Luo, Yuge Zhang, Zhiyuan He, Zilong Wang, Siyun Zhao, Dongsheng Li, Luna K Qiu, and Yuqing Yang. Agent lightning: Train any ai agents with reinforcement learning. arXiv preprint arXiv:2508.03680, 2025.
- Mialon et al. [2023] Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. In The Twelfth International Conference on Learning Representations, 2023.
- AIME [2025] AIME. Aime problems and solutions, 2025. URL https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions.
- Yao et al. [2022] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations, 2022.
- Yu et al. [2025] Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025.
- Mai et al. [2025] Xinji Mai, Haotian Xu, Weinong Wang, Jian Hu, Yingying Zhang, Wenqiang Zhang, et al. Agent rl scaling law: Agent rl with spontaneous code execution for mathematical problem solving. arXiv preprint arXiv:2505.07773, 2025.
- Xue et al. [2025] Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun Ma, and Bo An. Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning. arXiv preprint arXiv:2509.02479, 2025.
- Feng et al. [2025] Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms. arXiv preprint arXiv:2504.11536, 2025.
- Li et al. [2025] Weizhen Li, Jianbo Lin, Zhuosong Jiang, Jingyi Cao, Xinpeng Liu, Jiayu Zhang, Zhenqiang Huang, Qianben Chen, Weichen Sun, Qiexiang Wang, et al. Chain-of-agents: End-to-end agent foundation models via multi-agent distillation and agentic rl. arXiv preprint arXiv:2508.13167, 2025.
- Jin et al. [2025] Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516, 2025.
- Hong et al. [2023] Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. In The Twelfth International Conference on Learning Representations, 2023.
- Wu et al. [2024] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. In First Conference on Language Modeling, 2024.
- Qian et al. [2024] Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15174–15186, 2024.
- Hu et al. [2024] Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. arXiv preprint arXiv:2408.08435, 2024.
- Chen et al. [2023] Guangyao Chen, Siwei Dong, Yu Shu, Ge Zhang, Jaward Sesay, Börje F Karlsson, Jie Fu, and Yemin Shi. Autoagents: A framework for automatic agent generation. arXiv preprint arXiv:2309.17288, 2023.
- Shinn et al. [2023] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36:8634–8652, 2023.
- Schick et al. [2023] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36:68539–68551, 2023.
- Patil et al. [2024] Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis. Advances in Neural Information Processing Systems, 37:126544–126565, 2024.