SimpleMem: Efficient Lifelong Memory for LLM Agents
Abstract
To support reliable long-term interaction in complex environments, LLM agents require memory systems that efficiently manage historical experiences. Existing approaches either retain full interaction histories via passive context extension, leading to substantial redundancy, or rely on iterative reasoning to filter noise, incurring high token costs. To address this challenge, we introduce SimpleMem, an efficient memory framework based on semantic lossless compression. We propose a three-stage pipeline designed to maximize information density and token utilization: (1) Semantic Structured Compression, which applies entropy-aware filtering to distill unstructured interactions into compact, multi-view indexed memory units; (2) Recursive Memory Consolidation, an asynchronous process that integrates related units into higher-level abstract representations to reduce redundancy; and (3) Adaptive Query-Aware Retrieval, which dynamically adjusts retrieval scope based on query complexity to construct precise context efficiently. Experiments on benchmark datasets show that our method consistently outperforms baseline approaches in accuracy, retrieval efficiency, and inference cost, achieving an average F1 improvement of 26.4% while reducing inference-time token consumption by up to 30×, demonstrating a superior balance between performance and efficiency. Code is available at https://github.com/aiming-lab/SimpleMem.
1 Introduction
Large Language Model (LLM) agents have recently demonstrated remarkable capabilities across a wide range of tasks (Xia et al., 2025; Team et al., 2025; Qiu et al., 2025). However, constrained by fixed context windows, existing agents exhibit significant limitations when engaging in long-context and multi-turn interaction scenarios (Liu et al., 2023; Wang et al., 2024a; Liu et al., 2025; Hu et al., 2025; Tu et al., 2025). To facilitate reliable long-term interaction, LLM agents require robust memory systems to efficiently manage and utilize historical experience (Dev & Taranjeet, 2024; Fang et al., 2025; Wang & Chen, 2025; Tang et al., 2025; Yang et al., 2025; Ouyang et al., 2025).
While recent research has extensively explored the design of memory modules for LLM agents, current systems still suffer from suboptimal retrieval efficiency and low token utilization (Fang et al., 2025; Hu et al., 2025). On one hand, many existing systems maintain complete interaction histories through full-context extension (Li et al., 2025; Zhong et al., 2024). However, this approach introduce substantial redundant information (Hu et al., 2025). Specifically, during long-horizon interactions, user inputs and model responses accumulate substantial low-entropy noise (e.g., repetitive logs, non-task-oriented dialogue), which degrades the effective information density of the memory buffer. This redundancy adversely affects memory retrieval and downstream reasoning, often leading to middle-context degradation phenomena (Liu et al., 2023), while also incurring significant computational overhead during retrieval and secondary inference. On the other hand, some agentic frameworks mitigate noise through online filtering based on iterative reasoning procedures (Yan et al., 2025; Packer et al., 2023). Although such approaches improve retrieval relevance, they rely on repeated inference cycles, resulting in substantial computational cost, including increased latency and token usage. As a result, neither paradigm achieves efficient allocation of memory and computation resources.
To address these limitations, we introduce SimpleMem, an efficient memory framework inspired by the Complementary Learning Systems (CLS) theory (Kumaran et al., 2016) and designed around structured semantic compression. The core objective of SimpleMem is to improve information efficiency under fixed context and token budgets. To this end, we develop a three-stage pipeline that supports dynamic memory compression, organization, and adaptive retrieval: (1) Semantic Structured Compression: we apply an entropy-aware filtering mechanism that preserves information with high semantic utility while discarding redundant or low-value content. The retained information is reformulated into compact memory units and jointly indexed using dense semantic embeddings, sparse lexical features, and symbolic metadata, enabling multi-granular retrieval. (2) Recursive Memory Consolidation: Inspired by biological consolidation, we introduce an asynchronous process that incrementally reorganizes stored memory. Rather than accumulating episodic records verbatim, related memory units are recursively integrated into higher-level abstract representations, allowing repetitive or structurally similar experiences to be summarized while reducing semantic redundancy. (3) Adaptive Query-Aware Retrieval: we employ a query-aware retrieval strategy that dynamically adjusts retrieval scope based on estimated query complexity. Irrelevant candidates are pruned through lightweight symbolic and semantic constraints, enabling precise context construction tailored to task requirements. This adaptive mechanism achieves a favorable trade-off between reasoning performance and token efficiency.
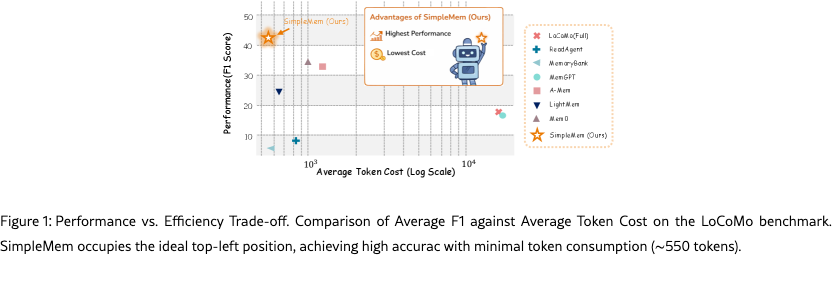
Our primary contribution is SimpleMem, an efficient memory framework grounded in structured semantic compression, which improves information efficiency through principled memory organization, consolidation, and adaptive retrieval. As shown in Figure 1, our empirical experiments demonstrate that SimpleMem establishes a new state-of-the-art with an F1 score, outperforming strong baselines like Mem0 by 26.4%, while reducing inference token consumption by 30 compared to full-context models.
2 The SimpleMem Architecture
In this section, we present SimpleMem, an efficient memory framework for LLM agents designed to improve information utilization under constrained context and token budgets through. As shown in Figure 2, the system operates through a three-stage pipeline. First, we describe Semantic Structured Compression process, which filters redundant interaction content and reformulates raw dialogue streams into compact memory units. Next, we describe Recursive Consolidation, an asynchronous process that incrementally integrates related memory units into higher-level abstract representations and maintaining a compact memory topology. Finally, we present Adaptive Query-Aware Retrieval, which dynamically adjusts retrieval scope based on estimated query complexity to construct precise and token-efficient contexts for downstream reasoning.
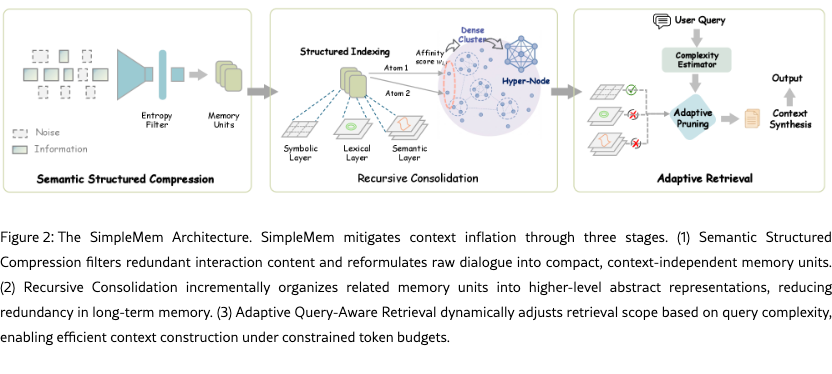
2.1 Semantic Structured Compression
A primary bottleneck in long-term interaction is context inflation, the accumulation of raw, low-entropy dialogue. For example, a large portion of interaction segments in the real-world consists of phatic chit-chat or redundant confirmations, which contribute little to downstream reasoning but consume substantial context capacity. To address this, we introduce a mechanism to actively filter and restructure information at the source.
First, incoming dialogue is segmented into overlapping sliding windows of fixed length, where each window represents a short contiguous span of recent interaction. These windows serve as the basic units for evaluating whether new information should be stored. Then we employ a non-linear gating mechanism, , to evaluate the information density of these dialogue windows to determine which windows is used fo indexing. For each window , we compute an information score that jointly captures the introduction of new entities and semantic novelty relative to the immediate interaction history .
Formally, let denote the set of named entities that appear in but not in . The information score is defined as:
| (1) |
where denotes a semantic embedding function and controls the relative importance of entity-level novelty and semantic divergence.
Windows whose information score falls below threshold are treated as redundant and excluded from memory construction, meaning that the window is neither stored nor further processed, preventing low-utility interaction content from entering the memory buffer. For informative windows, the system proceeds to a segmentation step:
| (2) |
For windows that pass the filter, we apply a segmentation function to decompose each informative window into a set of context-independent memory units . This transformation resolves dependencies implicit in conversational flow by converting entangled dialogue into self-contained factual or event-level statements. Formally, is composed of a coreference resolution module () and a temporal anchoring module ():
| (3) |
Here, identifies candidate factual statements, () replaces ambiguous pronouns with specific entity names (e.g., changing "He agreed" to "Bob agreed"), and converts relative temporal expressions (e.g., transforming "next Friday" to "2025-10-24") into absolute ISO-8601 timestamps. This normalization ensures that each memory unit remains interpretable and valid independent of its original conversational context.
2.2 Structured Indexing and Recursive Consolidation
Then, the system need organize the resulting memory units to support efficient long-term storage and scalable retrieval. This stage consists of two components: (i) structured multi-view indexing for immediate access, and (ii) recursive consolidation for reducing redundancy and maintaining a compact memory topology over time.
To support flexible and precise retrieval, each memory unit is indexed through three complementary representations. First, at sematic layer, we map the entry to a dense vector space using embedding models, which captures abstract meaning and enables fuzzy matching (e.g., retrieving "latte" when querying "hot drink"). Second, the Lexical Layer generates a sparse representation focusing on exact keyword matches and proper nouns, ensuring that specific entities are not diluted in vector space. Third, the Symbolic Layer extracts structured metadata, such as timestamps and entity types, to enable deterministic filtering logic. Formally, these projections form the comprehensive memory bank :
| (4) |
It allows the system to flexibly query information based on conceptual similarity, exact keyword matches, or structured metadata constraints.
While multi-view indexing supports efficient access, naively accumulating memory units over long interaction horizons leads to redundancy and fragmentation. To address this issue, we then introduces an asynchronous background consolidation process that incrementally reorganizes the memory topology. The consolidation mechanism identifies related memory units based on both semantic similarity and temporal proximity. For two memory units and , we define an affinity score as:
| (5) |
where the first term captures semantic relatedness and the second term biases the model toward grouping events with strong temporal proximity.
When a group of memory units forms a dense cluster , determined by pairwise affinities exceeding a threshold , the system performs a consolidation step:
| (6) |
This operation synthesizes repetitive or closely related memory units into a higher-level abstract representation , which captures their shared semantic structure. For example, instead of maintaining numerous individual records such as ‘‘the user ordered a latte at 8:00 AM,’’ the system consolidates them into a single abstract pattern, e.g., ‘‘the user regularly drinks coffee in the morning.’’ The original fine-grained entries are archived, reducing the active memory size while preserving the ability to recover detailed information if needed. As a result, the active memory index remains compact, and retrieval complexity scales gracefully with long-term interaction history.
2.3 Adaptive Query-Aware Retrieval
After memory entries are organized, another challenge to retrieve relevant information efficiently under constrained context budgets. Standard retrieval approaches typically fetch a fixed number of context entries, which often results in either insufficient information or token wastage. To address this, we introduces an adaptive query-aware retrieval mechanism that dynamically adjusts retrieval scope based on estimated query complexity, thereby improving retrieval efficiency without sacrificing reasoning accuracy.
First, we propose a hybrid scoring function for information retrieval, , which aggregates signals from the tri-layer index established in the second stage. For a given query , the relevance score is computed as:
| (7) | ||||
where the first term measures semantic similarity in the dense embedding space, the second term captures exact lexical relevance, and the indicator function enforces hard symbolic constraints such as entity-based filters.
Then, based on the hybrid scoring, we can rank the candidate memories by relevance. However, retrieving a fixed number of top-ranked entries remains inefficient when query demands vary. To address this, we estimate the query complexity , which reflects whether a query can be resolved via direct fact lookup or requires multi-step reasoning over multiple memory entries. A lightweight classifier predicts based on query features such as length, syntactic structure, and abstraction level.
| (8) |
Based on this dynamic depth, the system modulates the retrieval scope. For low-complexity queries (), the system retrieves only the top- high-level abstract memory entries or metadata summaries, minimizing token usage. Conversely, for high-complexity queries (), it expands the scope to top-, including a larger set of relevant entries, along with associated fine-grained details. The final context is synthesized by concatenating these pruned results, ensuring high accuracy with minimal computational waste:
| (9) |
3 Experiments
In this section, we evaluate SimpleMem on the benchmark to answer the following research questions: (1) Does SimpleMem outperform other memory systems in complex long-term reasoning and temporal grounding tasks? (2) Can SimpleMem achieve a superior trade-off between retrieval accuracy and token consumption? (3) How effective are the proposed components? (4) What factors account for the observed performance and efficiency gains?
3.1 Experimental Setup
Benchmark Dataset. We utilize the LoCoMo benchmark (Maharana et al., 2024), which is specifically designed to test the limits of LLMs in processing long-term conversational dependencies. The dataset comprises conversation samples ranging from 200 to 400 turns, containing complex temporal shifts and interleaved topics. The evaluation set consists of 1,986 questions categorized into four distinct reasoning types: (1) Multi-Hop Reasoning: Questions requiring the synthesis of information from multiple disjoint turns (e.g., ‘‘Based on what X said last week and Y said today...’’); (2) Temporal Reasoning: Questions testing the model’s ability to understand event sequencing and absolute timelines (e.g., ‘‘Did X happen before Y?’’); (3) Open Domain: General knowledge questions grounded in the conversation context; (4) Single Hop: Direct retrieval tasks requiring exact matching of specific facts.
Baselines. We compare SimpleMem with representative memory-augmented systems: LoCoMo (Maharana et al., 2024), ReadAgent (Lee et al., 2024), MemoryBank (Zhong et al., 2024), MemGPT (Packer et al., 2023), A-Mem (Xu et al., 2025), LightMem (Fang et al., 2025), and Mem0 (Dev & Taranjeet, 2024).
Backbone Models. To test robustness across capability scales, we instantiate each baseline and SimpleMem on multiple LLM backends: GPT-4o, GPT-4.1-mini, Qwen-Plus, Qwen2.5 (1.5B/3B), and Qwen3 (1.7B/8B).
Implementation Details. For semantic structured compression, we use a sliding window of size and set the entropy-based significance threshold to to filter low-information interaction content. Memory indexing is implemented using LanceDB with a multi-view design: text-embedding-3-small (1536 dimensions) for dense semantic embeddings, BM25 for sparse lexical indexing, and SQL-based metadata storage for symbolic attributes. Recursive consolidation is triggered when the average pairwise semantic similarity within a memory cluster exceeds . During retrieval, we employ adaptive query-aware retrieval, where the retrieval depth is dynamically adjusted based on estimated query complexity, ranging from for simple lookups to for complex reasoning queries.
Evaluation Metrics. We report: F1 and BLEU-1 (accuracy), Adversarial Success Rate (robustness to distractors), and Token Cost (retrieval/latency efficiency). LongMemEval-S uses its standard accuracy-style metric.
3.2 Main Results and Analysis
We evaluate SimpleMem across a diverse set of LLMs, ranging from high-capability proprietary models (GPT-4o series) to efficient open-source models (Qwen series). Tables 1 and 2 present the detailed performance comparison on the LoCoMo benchmark.
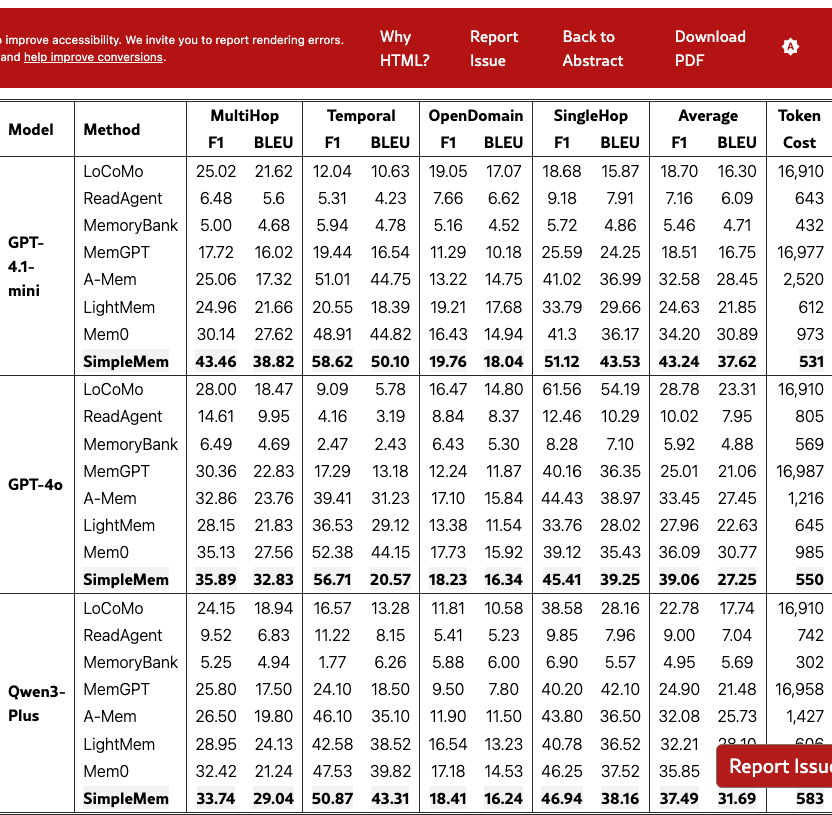
Performance on High-Capability Models. As shown in Table 1, SimpleMem consistently outperforms existing memory systems across all evaluated models. On GPT-4.1-mini, SimpleMem achieves an Average F1 of 43.24, establishing a significant margin over the strongest baseline, Mem0 (34.20), and surpassing the full-context baseline (LoCoMo, 18.70) by over 24 points. Notable gains are observed in Temporal Reasoning, where SimpleMem scores 58.62 F1 compared to Mem0’s 48.91, demonstrating the effectiveness of our Semantic Structured Compression in resolving complex timelines. Similarly, on the flagship GPT-4o, SimpleMem maintains its lead with an Average F1 of 39.06, outperforming Mem0 (36.09) and A-Mem (33.45). These results confirm that Recursive Consolidation mechanism effectively distills high-density knowledge, enabling even smaller models equipped with SimpleMem to outperform larger models using traditional memory systems.
Token Efficiency. A key strength of SimpleMem lies in its inference-time efficiency. As reported in the rightmost columns of Tables 1 and 2, full-context approaches such as LoCoMo and MemGPT consume approximately 16,900 tokens per query. In contrast, SimpleMem reduces token usage by roughly , averaging 530–580 tokens per query. Furthermore, compared to optimized retrieval baselines like Mem0 (980 tokens) and A-Mem (1,200+ tokens), SimpleMem reduces token usage by 40-50% while delivering superior accuracy. For instance, on GPT-4.1-mini, SimpleMem uses only 531 tokens to achieve state-of-the-art performance, whereas ReadAgent consumes more (643 tokens) but achieves far lower accuracy (7.16 F1). This validates the efficacy of our Entropy-based Filtering and Adaptive Pruning, which strictly control context bandwidth without sacrificing information density.
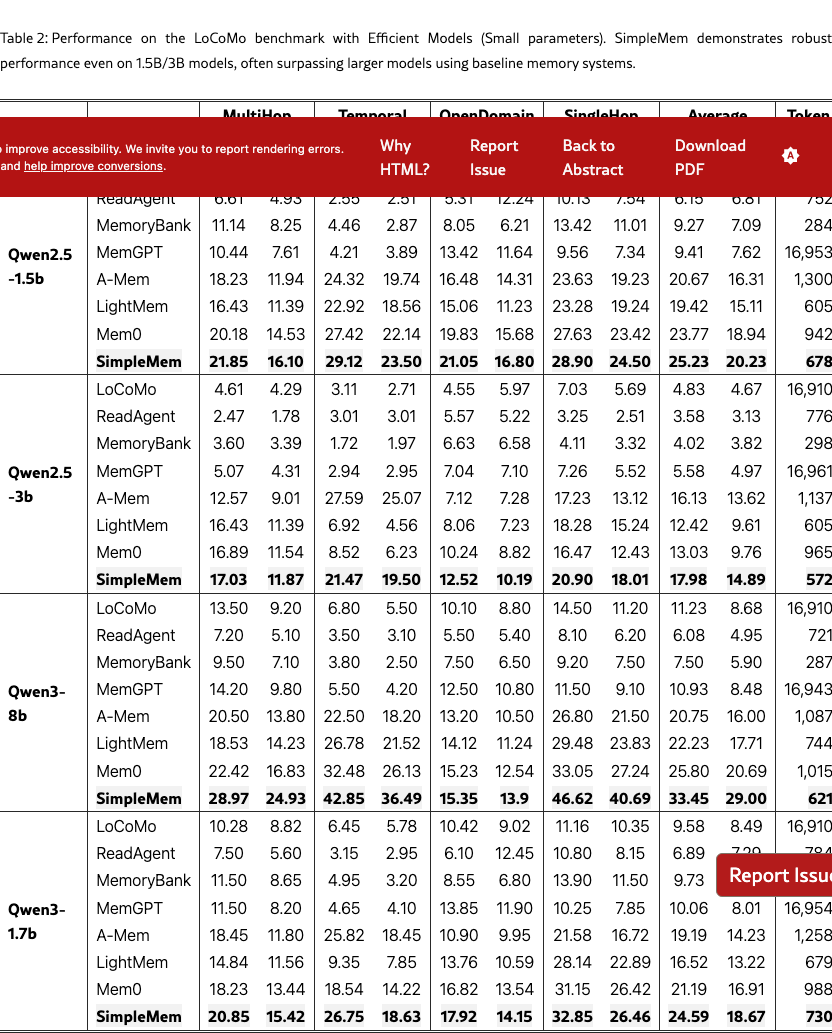
Performance on Smaller Models. Table 2 highlights the ability of SimpleMem to empower smaller parameter models. On Qwen3-8b, SimpleMem achieves an impressive Average F1 of 33.45, significantly surpassing Mem0 (25.80) and LightMem (22.23). Crucially, a 3B-parameter model (Qwen2.5-3b) paired with SimpleMem achieves 17.98 F1, outperforming the same model with Mem0 (13.03) by nearly 5 points. Even on the extremely lightweight Qwen2.5-1.5b, SimpleMem maintains robust performance (25.23 F1), beating larger models using inferior memory strategies (e.g., Qwen3-1.7b with Mem0 scores 21.19).
Robustness Across Task Types. Breaking down performance by task, SimpleMem demonstrates balanced capabilities. In SingleHop QA, it consistently leads (e.g., 51.12 F1 on GPT-4.1-mini), proving precision in factual retrieval. In complex MultiHop scenarios, SimpleMem significantly outperforms Mem0 and LightMem on GPT-4.1-mini, indicating that our Molecular Representations successfully bridge disconnected facts, enabling deep reasoning without the need for expensive iterative retrieval loops.
3.3 Efficiency Analysis
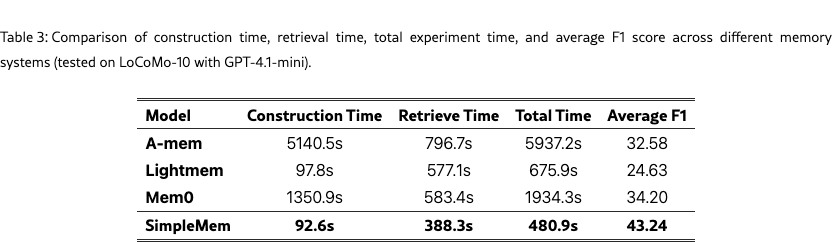
We conduct a comprehensive evaluation of computational efficiency, examining both end-to-end system latency and the scalability of memory indexing and retrieval. To assess practical deployment viability, we measured the full lifecycle costs on the LoCoMo-10 dataset using GPT-4.1-mini.
As illustrated in Table 3, SimpleMem exhibits superior efficiency across all operational phases. In terms of memory construction, our system achieves the fastest processing speed at 92.6 seconds per sample. This represents a dramatic improvement over existing baselines, outperforming Mem0 by approximately 14 (1350.9s) and A-Mem by over 50 (5140.5s). This massive speedup is directly attributable to our Semantic Structured Compression pipeline, which processes data in a streamlined single pass, thereby avoiding the complex graph updates required by Mem0 or the iterative summarization overheads inherent to A-Mem.
Beyond construction, SimpleMem also maintains the lowest retrieval latency at 388.3 seconds per sample, which is approximately 33% faster than LightMem and Mem0. This gain arises from the adaptive retrieval mechanism, which dynamically limits retrieval scope and prioritizes high-level abstract representations before accessing fine-grained details. By restricting retrieval to only the most relevant memory entries, the system avoids the expensive neighbor traversal and expansion operations that commonly dominate the latency of graph-based memory systems.
When considering the total time-to-insight, SimpleMem achieves a 4 speedup over Mem0 and a 12 speedup over A-Mem. Crucially, this efficiency does not come at the expense of performance. On the contrary, SimpleMem achieves the highest Average F1 among all compared methods. These results support our central claim that structured semantic compression and adaptive retrieval produce a more compact and effective reasoning substrate than raw context retention or graph-centric memory designs, enabling a superior balance between accuracy and computational efficiency.
3.4 Ablation Study
To verify the claims that specific cognitive mechanisms correspond to computational gains, we conducted a component-wise ablation study using the GPT-4.1-mini backend. We investigate the contribution of three key components: (1) Semantic Structured Compression , (2) Recursive Consolidation, and (3) Adaptive Query-Aware Retrieval. The results are summarized in Table 4.
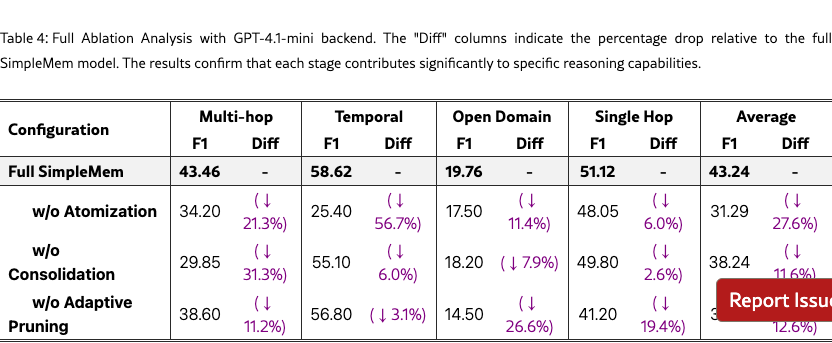
Impact of Semantic Structured Compression. Replacing the proposed compression pipeline with standard chunk-based storage leads to a substantial degradation in temporal reasoning performance. Specifically, removing semantic structured compression reduces the Temporal F1 by 56.7%, from 58.62 to 25.40. This drop indicates that without context normalization steps such as resolving coreferences and converting relative temporal expressions into absolute timestamps, the retriever struggles to disambiguate events along the timeline. As a result, performance regresses to levels comparable to conventional retrieval-augmented generation systems that rely on raw or weakly structured context.
Impact of Recursive Consolidation. Disabling the background consolidation process results in a 31.3% decrease in multi-hop reasoning performance. Without consolidating related memory units into higher-level abstract representations, the system must retrieve a larger number of fragmented entries during reasoning. This fragmentation increases context redundancy and exhausts the available context window in complex queries, demonstrating that recursive consolidation is essential for synthesizing dispersed evidence into compact and informative representations.
Impact of Adaptive Query-Aware Retrieval. Removing the adaptive retrieval mechanism and reverting to fixed-depth retrieval primarily degrades performance on open-domain and single-hop tasks, with drops of 26.6% and 19.4%, respectively. In the absence of query-aware adjustment, the system either retrieves insufficient context for entity-specific queries or introduces excessive irrelevant information for simple queries. These results highlight the importance of dynamically modulating retrieval scope to balance relevance and efficiency during inference.
3.5 Case Study: Long-Term Temporal Grounding
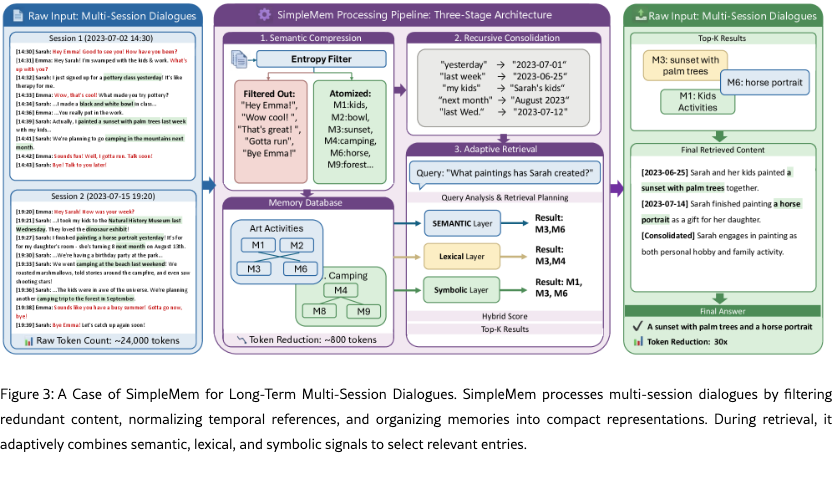
To illustrate how SimpleMem handles long-horizon conversational history, Figure 3 presents a representative multi-session example spanning two weeks and approximately 24,000 raw tokens. SimpleMem filters low-information dialogue during ingestion and retains only high-utility memory entries, reducing the stored memory to about 800 tokens without losing task-relevant content.
Temporal Normalization. Relative temporal expressions such as last week” and yesterday” refer to different absolute times across sessions. SimpleMem resolves it into absolute timestamps at memory construction time, ensuring consistent temporal grounding over long interaction gaps.
Precise Retrieval. When queried about Sarah’s past artworks, the adaptive retrieval mechanism combines semantic relevance with symbolic constraints to exclude unrelated activities and retrieve only temporally valid entries. The system correctly identifies relevant paintings while ignoring semantically related but irrelevant topics. This example demonstrates how structured compression, temporal normalization, and adaptive retrieval jointly enable reliable long-term reasoning under extended interaction histories.
4 Related Work
Memory Systems for LLM Agents. Recent approaches manage memory through virtual context or structured representations. Virtual context methods, including MemGPT (Packer et al., 2023), MemoryOS (Kang et al., 2025), and SCM (Wang et al., 2023), extend interaction length via paging or stream-based controllers (Wang et al., 2024b) but typically store raw conversation logs, leading to redundancy and increasing processing costs. In parallel, structured and graph-based systems, such as MemoryBank (Zhong et al., 2024), Mem0 (Dev & Taranjeet, 2024), Zep (Rasmussen et al., 2025), A-Mem (Xu et al., 2025), and O-Mem (Wang et al., 2025), impose structural priors to improve coherence but still rely on raw or minimally processed text, preserving referential and temporal ambiguities that degrade long-term retrieval. In contrast, SimpleMem adopts a semantic compression mechanism that converts dialogue into independent, self-contained facts, explicitly resolving referential and temporal ambiguities prior to storage.
Context Management and Retrieval Efficiency. Beyond memory storage, efficient access to historical information remains a core challenge. Existing approaches primarily rely on either long-context models or retrieval-augmented generation (RAG). Although recent LLMs support extended context windows (OpenAI, 2025; Deepmind, 2025; Anthropic, 2025), and prompt compression methods aim to reduce costs (Jiang et al., 2023a; Liskavetsky et al., 2025), empirical studies reveal the “Lost-in-the-Middle” effect (Liu et al., 2023; Kuratov et al., 2024), where reasoning performance degrades as context length increases, alongside prohibitive computational overhead for lifelong agents. RAG-based methods (Lewis et al., 2020; Asai et al., 2023; Jiang et al., 2023b), including structurally enhanced variants such as GraphRAG (Edge et al., 2024; Zhao et al., 2025) and LightRAG (Guo et al., 2024), decouple memory from inference but are largely optimized for static knowledge bases, limiting their effectiveness for dynamic, time-sensitive episodic memory. In contrast, SimpleMem improves retrieval efficiency through Adaptive Pruning and Retrieval, jointly leveraging semantic, lexical, and metadata signals to enable precise filtering by entities and timestamps, while dynamically adjusting retrieval depth based on query complexity to minimize token usage.
5 Conclusion
We introduce SimpleMem, an efficient memory architecture governed by the principle of Semantic Lossless Compression. By reimagining memory as a metabolic process, SimpleMem implements a dynamic continuum: Semantic Structured Compression to filter noise at the source, Recursive Consolidation to evolve fragmented facts into high-order molecular insights, and Adaptive Spatial Pruning to dynamically modulate retrieval bandwidth. Empirical evaluation on the LoCoMo benchmark demonstrates the effectiveness and efficiency of SimpleMem.
Acknowledgement
This work is partially supported by Amazon Research Award, Cisco Faculty Research Award, and Coefficient Giving.
References
- Anthropic (2025) Anthropic. Claude 3.7 sonnet and claude code. https://www.anthropic.com/news/claude-3-7-sonnet, 2025.
- Asai et al. (2023) Asai, A., Wu, Z., Wang, Y., Sil, A., and Hajishirzi, H. Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023.
- Deepmind (2025) Deepmind, G. Gemini 2.5: Our most intelligent AI model — blog.google. https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/#gemini-2-5-thinking, 2025. Accessed: 2025-03-25.
- Dev & Taranjeet (2024) Dev, K. and Taranjeet, S. mem0: The memory layer for ai agents. https://github.com/mem0ai/mem0, 2024.
- Edge et al. (2024) Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., and Larson, J. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024.
- Fang et al. (2025) Fang, J., Deng, X., Xu, H., Jiang, Z., Tang, Y., Xu, Z., Deng, S., Yao, Y., Wang, M., Qiao, S., et al. Lightmem: Lightweight and efficient memory-augmented generation. arXiv preprint arXiv:2510.18866, 2025.
- Guo et al. (2024) Guo, Z., Xia, L., Yu, Y., Ao, T., and Huang, C. Lightrag: Simple and fast retrieval-augmented generation. arXiv preprint arXiv:2410.05779, 2024.
- Hu et al. (2025) Hu, Y., Liu, S., Yue, Y., Zhang, G., Liu, B., Zhu, F., Lin, J., Guo, H., Dou, S., Xi, Z., et al. Memory in the age of ai agents. arXiv preprint arXiv:2512.13564, 2025.
- Jiang et al. (2023a) Jiang, H., Wu, Q., Lin, C.-Y., Yang, Y., and Qiu, L. Llmlingua: Compressing prompts for accelerated inference of large language models. arXiv preprint arXiv:2310.05736, 2023a.
- Jiang et al. (2023b) Jiang, Z., Xu, F. F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J., Yang, Y., Callan, J., and Neubig, G. Active retrieval augmented generation. arXiv preprint arXiv:2305.06983, 2023b.
- Kang et al. (2025) Kang, J., Ji, M., Zhao, Z., and Bai, T. Memory os of ai agent. arXiv preprint arXiv:2506.06326, 2025.
- Kumaran et al. (2016) Kumaran, D., Hassabis, D., and McClelland, J. L. What learning systems do intelligent agents need? complementary learning systems theory updated. Trends in cognitive sciences, 20(7):512–534, 2016.
- Kuratov et al. (2024) Kuratov, Y. et al. In case of context: Investigating the effects of long context on language model performance. arXiv preprint, 2024.
- Lee et al. (2024) Lee, K.-H., Chen, X., Furuta, H., Canny, J., and Fischer, I. A human-inspired reading agent with gist memory of very long contexts. arXiv preprint arXiv:2402.09727, 2024.
- Lewis et al. (2020) Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Li et al. (2025) Li, Z., Song, S., Wang, H., Niu, S., Chen, D., Yang, J., Xi, C., Lai, H., Zhao, J., Wang, Y., Ren, J., Lin, Z., Huo, J., Chen, T., Chen, K., Li, K.-R., Yin, Z., Yu, Q., Tang, B., Yang, H., Xu, Z., and Xiong, F. Memos: An operating system for memory-augmented generation (mag) in large language models. ArXiv, abs/2505.22101, 2025. URL https://api.semanticscholar.org/CorpusID:278960153.
- Liskavetsky et al. (2025) Liskavetsky, A. et al. Compressor: Context-aware prompt compression for enhanced llm inference. arXiv preprint, 2025.
- Liu et al. (2025) Liu, J., Xiong, K., Xia, P., Zhou, Y., Ji, H., Feng, L., Han, S., Ding, M., and Yao, H. Agent0-vl: Exploring self-evolving agent for tool-integrated vision-language reasoning. arXiv preprint arXiv:2511.19900, 2025.
- Liu et al. (2023) Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., and Liang, P. Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172, 2023.
- Maharana et al. (2024) Maharana, A., Lee, D.-H., Tulyakov, S., Bansal, M., Barbieri, F., and Fang, Y. Evaluating very long-term conversational memory of llm agents, 2024. URL https://arxiv.org/abs/2402.17753.
- OpenAI (2025) OpenAI. Introducing gpt-5. https://openai.com/index/introducing-gpt-5/, 2025.
- Ouyang et al. (2025) Ouyang, S., Yan, J., Hsu, I., Chen, Y., Jiang, K., Wang, Z., Han, R., Le, L. T., Daruki, S., Tang, X., et al. Reasoningbank: Scaling agent self-evolving with reasoning memory. arXiv preprint arXiv:2509.25140, 2025.
- Packer et al. (2023) Packer, C., Fang, V., Patil, S. G., Lin, K., Wooders, S., and Gonzalez, J. Memgpt: Towards llms as operating systems. ArXiv, abs/2310.08560, 2023. URL https://api.semanticscholar.org/CorpusID:263909014.
- Qiu et al. (2025) Qiu, J., Qi, X., Zhang, T., Juan, X., Guo, J., Lu, Y., Wang, Y., Yao, Z., Ren, Q., Jiang, X., et al. Alita: Generalist agent enabling scalable agentic reasoning with minimal predefinition and maximal self-evolution. arXiv preprint arXiv:2505.20286, 2025.
- Rasmussen et al. (2025) Rasmussen, P., Paliychuk, P., Beauvais, T., Ryan, J., and Chalef, D. Zep: a temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956, 2025.
- Tang et al. (2025) Tang, X., Qin, T., Peng, T., Zhou, Z., Shao, D., Du, T., Wei, X., Xia, P., Wu, F., Zhu, H., et al. Agent kb: Leveraging cross-domain experience for agentic problem solving. arXiv preprint arXiv:2507.06229, 2025.
- Team et al. (2025) Team, T. D., Li, B., Zhang, B., Zhang, D., Huang, F., Li, G., Chen, G., Yin, H., Wu, J., Zhou, J., et al. Tongyi deepresearch technical report. arXiv preprint arXiv:2510.24701, 2025.
- Tu et al. (2025) Tu, A., Xuan, W., Qi, H., Huang, X., Zeng, Q., Talaei, S., Xiao, Y., Xia, P., Tang, X., Zhuang, Y., et al. Position: The hidden costs and measurement gaps of reinforcement learning with verifiable rewards. arXiv preprint arXiv:2509.21882, 2025.
- Wang et al. (2023) Wang, B., Liang, X., Yang, J., Huang, H., Wu, S., Wu, P., Lu, L., Ma, Z., and Li, Z. Enhancing large language model with self-controlled memory framework. arXiv preprint arXiv:2304.13343, 2023.
- Wang et al. (2025) Wang, P., Tian, M., Li, J., Liang, Y., Wang, Y., Chen, Q., Wang, T., Lu, Z., Ma, J., Jiang, Y. E., et al. O-mem: Omni memory system for personalized, long horizon, self-evolving agents. arXiv e-prints, pp. arXiv–2511, 2025.
- Wang et al. (2024a) Wang, T., Tao, M., Fang, R., Wang, H., Wang, S., Jiang, Y. E., and Zhou, W. Ai persona: Towards life-long personalization of llms. arXiv preprint arXiv:2412.13103, 2024a.
- Wang & Chen (2025) Wang, Y. and Chen, X. Mirix: Multi-agent memory system for llm-based agents. arXiv preprint arXiv:2507.07957, 2025.
- Wang et al. (2024b) Wang, Z. Z., Mao, J., Fried, D., and Neubig, G. Agent workflow memory. arXiv preprint arXiv:2409.07429, 2024b.
- Xia et al. (2025) Xia, P., Zeng, K., Liu, J., Qin, C., Wu, F., Zhou, Y., Xiong, C., and Yao, H. Agent0: Unleashing self-evolving agents from zero data via tool-integrated reasoning. arXiv preprint arXiv:2511.16043, 2025.
- Xu et al. (2025) Xu, W., Liang, Z., Mei, K., Gao, H., Tan, J., and Zhang, Y. A-mem: Agentic memory for llm agents. ArXiv, abs/2502.12110, 2025. URL https://api.semanticscholar.org/CorpusID:276421617.
- Yan et al. (2025) Yan, B., Li, C., Qian, H., Lu, S., and Liu, Z. General agentic memory via deep research. arXiv preprint arXiv:2511.18423, 2025.
- Yang et al. (2025) Yang, B., Xu, L., Zeng, L., Liu, K., Jiang, S., Lu, W., Chen, H., Jiang, X., Xing, G., and Yan, Z. Contextagent: Context-aware proactive llm agents with open-world sensory perceptions. arXiv preprint arXiv:2505.14668, 2025.
- Zhao et al. (2025) Zhao, Y., Zhu, J., Guo, Y., He, K., and Li, X. Eˆ 2graphrag: Streamlining graph-based rag for high efficiency and effectiveness. arXiv preprint arXiv:2505.24226, 2025.
- Zhong et al. (2024) Zhong, W., Guo, L., Gao, Q., Ye, H., and Wang, Y. Memorybank: Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 19724–19731, 2024.
Appendix A Detailed System Prompts
To ensure full reproducibility of the SimpleMem pipeline, we provide the exact system prompts used in the key processing stages. All prompts are designed to be model-agnostic but were optimized for GPT-4o-mini in our experiments to ensure cognitive economy.
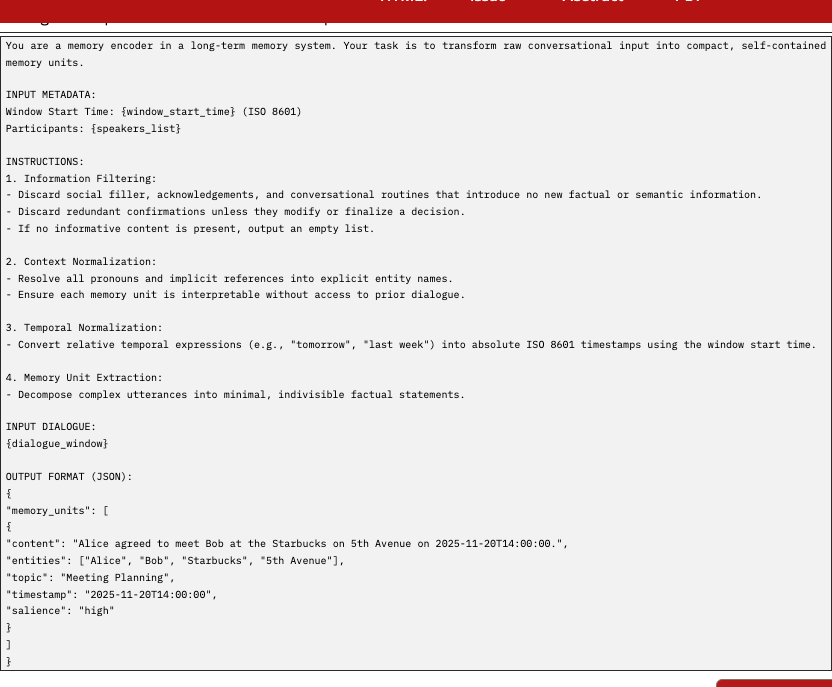
A.1 Stage 1: Semantic Structured Compression Prompt
This prompt performs entropy-aware filtering and context normalization. Its goal is to transform raw dialogue windows into compact, context-independent memory units while excluding low-information interaction content.
A.2 Stage 2: Adaptive Retrieval Planning Prompt
This prompt analyzes the user query prior to retrieval. Its purpose is to estimate query complexity and generate a structured retrieval plan that adapts retrieval scope accordingly.

A.3 Stage 3: Reconstructive Synthesis Prompt
This prompt guides the final answer generation using retrieved memory. It combines high-level abstract representations with fine-grained factual details to produce a grounded response.
Appendix B Extended Implementation Details and Experiments
B.1 Hyperparameter Configuration
B.2 Hyperparameter Sensitivity Analysis
To assess the effectiveness of semantic structured compression and to motivate the design of adaptive retrieval, we analyze system sensitivity to the number of retrieved memory entries (). We vary from 1 to 20 and report the average F1 score on the LoCoMo benchmark using the GPT-4.1-mini backend.
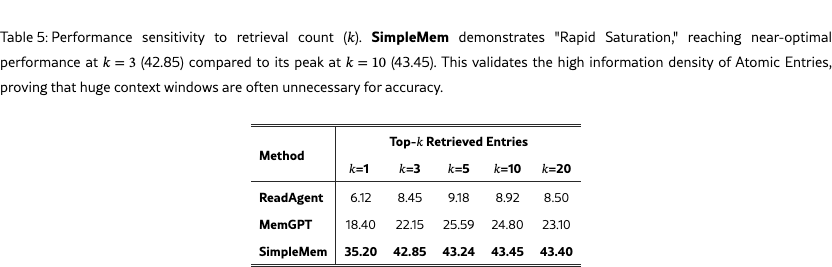
Table 5 provides two key observations. First, rapid performance saturation is observed at low retrieval depth. SimpleMem achieves strong performance with a single retrieved entry (35.20 F1) and reaches approximately 99% of its peak performance at . This behavior indicates that semantic structured compression produces memory units with high information content, often sufficient to answer a query without aggregating many fragments.
Second, robustness to increased retrieval depth distinguishes SimpleMem from baseline methods. While approaches such as MemGPT experience performance degradation at larger , SimpleMem maintains stable accuracy even when retrieving up to 20 entries. This robustness enables adaptive retrieval to safely expand context for complex reasoning tasks without introducing excessive irrelevant information.
