Black-Box On-Policy Distillation of
Large Language Models
Abstract
Black-box distillation creates student large language models (LLMs) by learning from a proprietary teacher model’s text outputs alone, without access to its internal logits or parameters. In this work, we introduce Generative Adversarial Distillation (GAD), which enables on-policy and black-box distillation. GAD frames the student LLM as a generator and trains a discriminator to distinguish its responses from the teacher LLM’s, creating a minimax game. The discriminator acts as an on-policy reward model that co-evolves with the student, providing stable, adaptive feedback. Experimental results show that GAD consistently surpasses the commonly used sequence-level knowledge distillation. In particular, Qwen2.5-14B-Instruct (student) trained with GAD becomes comparable to its teacher, GPT-5-Chat, on the LMSYS-Chat automatic evaluation. The results establish GAD as a promising and effective paradigm for black-box LLM distillation.

1 Introduction
Knowledge distillation [kd] in large language models (LLMs; gpt4, gpt5, deepseekv3, qwen3) is primarily used to create smaller, more efficient student models that retain much of the performance of a larger, resource-intensive teacher model. The setting in which the student has access to the teacher’s internal probability distribution or hidden states is called white-box distillation. Standard white-box approaches align the teacher and student by matching their output distributions, typically via Kullback-Leibler divergence (KLD) [lightpaff, minillm], or their inner states [tinybert, bert-pkd, minilm]. However, white-box access is often impractical when the teacher is a proprietary API model (e.g., GPT-5). In this scenario, only teacher-generated texts are accessible, defining the more challenging black-box distillation setting. The absence of fine-grained probability supervision makes conventional likelihood-based objectives unavailable. Typical black-box distillation methods simply perform supervised fine-tuning on teacher responses [alpaca, vicuna]. Furthermore, when the student and teacher employ incompatible tokenizers, applying likelihood-based objectives also becomes challenging. This highlights the need for a framework that can effectively extract deeper and richer knowledge from teacher-generated text responses.
Recent studies [minillm, googlepolicy, thinkingmachine-onpolicy, qwen3] in white-box distillation highlight the importance of on-policy learning, where the student learns from its own generated responses rather than solely imitating the teacher’s outputs. These studies show that performing reverse KLD on student-generated text promotes mode-seeking behavior and reduces exposure bias compared to teacher-forced training. However, extending this idea to the black-box setting introduces a major challenge: when the student produces its own responses, there are no probability-level supervision signals available from the teacher to evaluate or correct them. Without explicit feedback, the student cannot directly gauge the quality of its generations relative to the teacher, making effective on-policy distillation infeasible under the standard likelihood-based framework.
To address this limitation, we propose GAD, a Generative Adversarial Distillation framework that enables on-policy learning in the black-box regime. Our key idea is to view the student as a generator that produces responses conditioned on prompts, and to train a discriminator to distinguish between teacher and student outputs. The generator is then optimized to produce responses that the discriminator cannot distinguish from those of the teacher, forming a minimax game similar to generative adversarial networks (GANs; gan, seqgan). This adversarial process allows the student to receive implicit feedback on the quality of its own generations, even without access to the teacher’s probability space. Besides, from the perspective of reinforcement learning (RL; rlintro, ppo, trpo), our discriminator can be interpreted as an on-policy reward model that evolves jointly with the student policy. Unlike conventional reward models in RLHF [instruct-gpt] which are fixed after pretraining and prone to reward hacking [reward_hacking], our discriminator continually adapts to the student’s behavior during training. The on-policy reward modeling provides stable and dynamic supervision throughout the distillation process.
We validate our approach using GPT-5-Chat [gpt5] as a teacher and a range of open-source models from the Qwen2.5 [qwen2.5] and Llama3 [llama3] families as a student. Experiments are conducted on the a subset of LMSYS-Chat-1M dataset [lmsys] and evaluated across multiple domains. Under identical training budgets, GAD consistently outperforms both the instruction models before distillation and the SeqKD [skd, vicuna, alpaca, ITGPT4, lima] baseline across all datasets and model sizes. Notably, on GPT-4o score, Qwen2.5-3B-Instruct distilled with GAD matches the performance of Qwen2.5-7B-Instruct distilled with SeqKD, while Qwen2.5-14B-Instruct trained with GAD approaches the capability of the GPT-5 teacher itself. Our method also delivers particularly strong improvements in out-of-distribution generalization, where SeqKD yields marginal or negative gains. Human evaluations further confirm performance. GAD can effectively extract high-quality knowledge from black-box LLMs without access to output logits.
2 Method
We study conditional text generation of large language models, where a model generates a response conditioned on a given prompt sampled from dataset . To transfer the capabilities of large models to smaller ones, knowledge distillation (KD) trains a student distribution parameterized by to approximate the behavior of a teacher distribution . In the white-box distillation setting, the student has access to the teacher’s predictive distribution . Approaches such as forward KLD [skd, lightpaff, vicuna, alpaca] or reverse KLD [minillm] are designed for this setting. However, these techniques can fail if the teacher is a proprietary model that only returns generated text. We refer to this scenario as black-box distillation, where only textual responses from the teacher are observable. The goal is to learn a student model that imitates the teacher’s generative behavior without access to its internal probability space.
2.1 GAD: Generative Adversarial Distillation
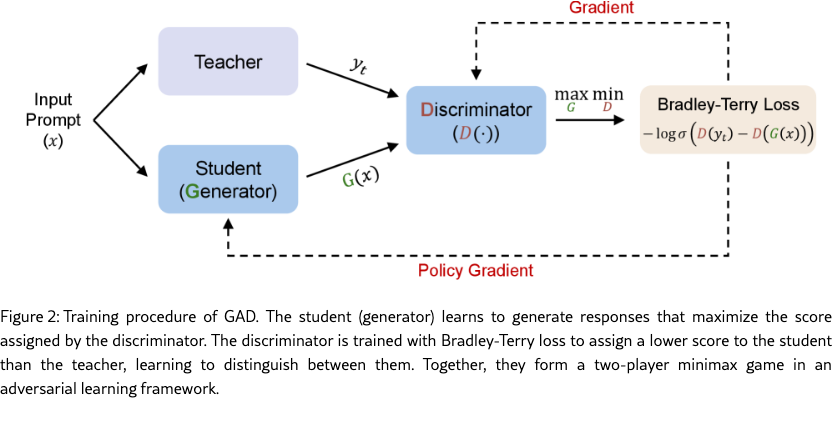
We perform black-box distillation with generative adversarial training [gan, seqgan] as shown in Figure˜2. The training dataset is constructed by iterating over the prompts in the original dataset and sampling a teacher response for each. Our framework consists of a generator which is the student model, and a discriminator that assesses the quality of the student and teacher responses. The generator generates the response to the prompt . The discriminator predicts a sequence-level scalar score given prompt and response 111 The input prompt and generated response are concatenated (i.e., ) and fed into the discriminator (i.e., ). For brevity, we use below to represent .. The discriminator is initialized using generator model parameters with an extra prediction head. The head projects the final hidden state to a scalar score, and the score of the last token in the sequence is taken as the sequence-level score. The training objective is formulated as a two-player minimax game with the following value function :
| (1) |
where denotes the sigmoid function. We use Bradley-Terry model [bradley] to capture pairwise preferences between teacher and student response. The proposed generative adversarial training framework allows the student to learn on-policy from its own generated responses via discriminator feedback, eliminating the need to access the teacher’s internal representations.
2.2 Training
We discuss the training algorithm of generator and discriminator respectively. From Equation (1), the generator is trained with the following objective:
| (2) |
Since the sampling operation in is non-differentiable with respect to the student model parameters, we treat as a reward and optimize it using policy gradient [policy_gradient] with established reinforcement learning algorithms. We employ GRPO [grpo] to train the student in our experiments, with detailed formulations provided in Appendix A.1. For the discriminator , we minimize its training loss derived from Equation (1):
| (3) |
The discriminator uses Bradley-Terry loss to capture pairwise preferences, encouraging higher scores for teacher responses over student-generated ones.
Warmup Before GAD Training
We find that jointly warming up the generator and discriminator before the GAD training stage is crucial for final performance. We fine-tune the student on the teacher’s response, and we minimize the cross-entropy loss as warmup for the generator. In the meanwhile, the discriminator is trained using the same data with the Bradley-Terry loss in Equation (3). We conduct warmup for both models for one epoch before starting GAD training. This step promotes effective adversarial optimization and ensures the balance between the generator and discriminator. Ablation studies on the warmup strategy are presented in Section˜3.4.
2.3 Implement GAD with Reinforcement Learning Frameworks
In our experiments, we implement GAD using existing reinforcement learning frameworks, such as verl [verl]. GRPO [grpo] is used as the policy gradient algorithm, which is detailed in Appendix A.1.
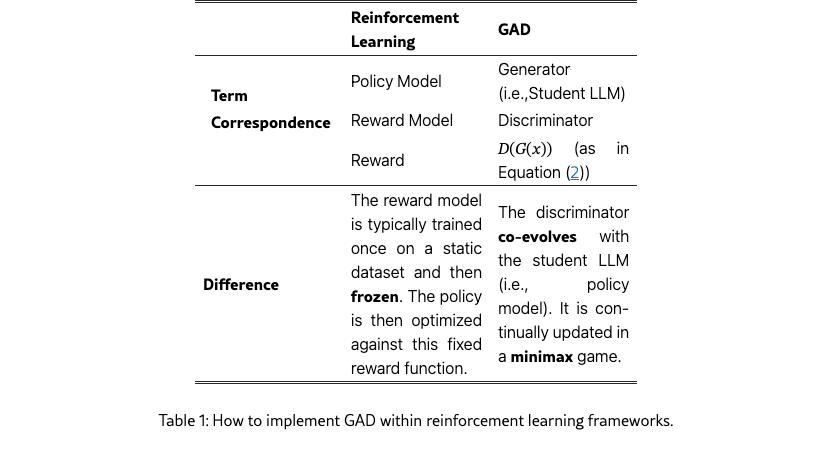
As presented in Table˜1, we implement the generator as a policy model and the discriminator as a reward model. The generator produces responses, receives rewards from the discriminator, and is optimized to maximize the expected reward. The reward is defined in Equation (2), i.e., .
Unlike vanilla reinforcement learning, GAD also needs to jointly update the discriminator (i.e., reward model). The discriminator is trained with Bradley-Terry loss on preference pairs to score the teacher response higher than the student’s output, similar to the reward model in RLHF [instruct-gpt]. While conventional RLHF trains a fixed reward model prior to policy optimization which is prone to reward hacking, our approach updates the reward model (discriminator) online to adapt it to the current policy continually.
Pseudocode of Training Algorithm
Algorithm 1 presents the pseudocode for GAD training.

3 Experiments
3.1 Setup
Dataset
Given a dataset of instruction prompts, we collect corresponding responses from a teacher model and use them to distill student models. For the following experiments, we use LMSYS-Chat-1M-Clean222 https://huggingface.co/datasets/OpenLeecher/lmsys_chat_1m_clean, a clean version of the LMSYS-Chat-1M dataset [lmsys]. The dataset is derived from high-quality conversational data collected via the Chatbot Arena333 https://lmarena.ai platform.
Teacher and Student Models
We adopt GPT-5-Chat [gpt5] as the teacher model. It is a closed-source chat model ranked ninth on the Chatbot Text Arena leaderboard at the time of writing. For student models, we use the instruction-tuned variants of open-source models from the Qwen2.5 [qwen2.5] family (Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct, Qwen2.5-14B-Instruct) and the Llama3 [llama3] family (Llama-3.2-3B-Instruct, Llama-3.1-8B-Instruct).
Training
For training data, we sample 200K samples from LMSYS-Chat-1M-Clean and collect the corresponding GPT-5-Chat responses to the instructions as teacher responses. All models are trained for 3 epochs with a batch size of 256, totaling approximately 2400 optimization steps. The PPO mini-batch size for each policy update is also 256. The maximum context length is set to 2048 tokens for instruction prompts and 1536 for model responses. The training and sampling temperature is set to . We save checkpoints every 50 steps. More training details can be found in Appendix A.2.
Evaluation
We reserve 500 samples of LMSYS-Chat-1M-Clean as the primary test set. We also include test datasets consisting of a 500-sample subset split from Dolly [dolly], the 252-sample SelfInst dataset [self_inst], and the 80-question Vicuna benchmark [vicuna] to evaluate out-of-distribution generalization. We report the GPT-4o evaluation scores [mtbench, minillm], where GPT-4o first generates reference answers and then scores the output of the student model against them. We also conduct human evaluations on the LMSYS-Chat-1M-Clean test set for qualitative assessment. We select the checkpoint that achieved the highest GPT-4o score and whose response length is within an acceptable range for each experiment. Detailed evaluation protocols are described in Appendix A.3.
3.2 Main Results
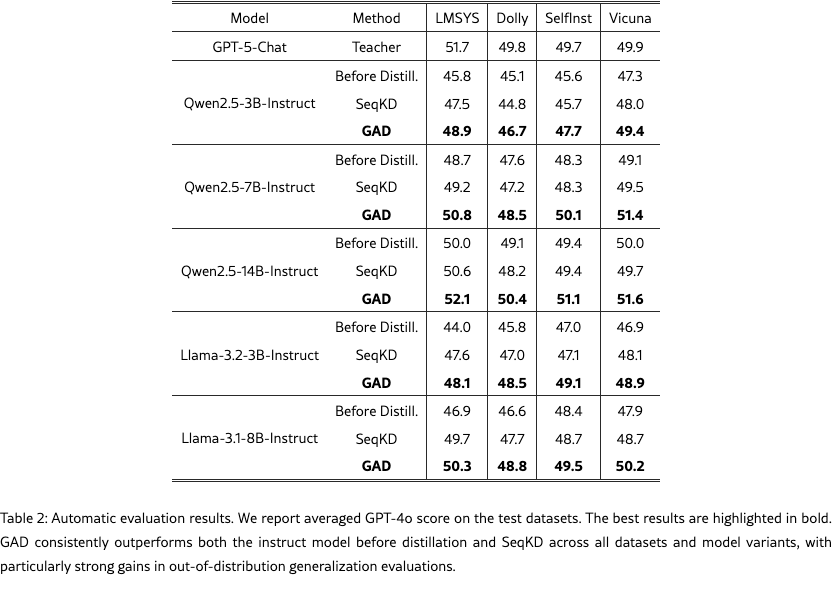
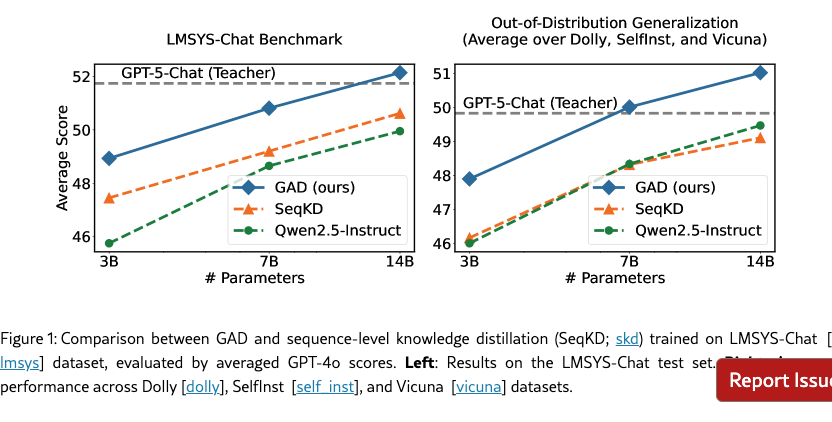
Automatic Evaluation
We report the results of automatic evaluation using GPT-4o scores in Figure˜1 and Table˜2. We compare GAD with the instruct model before distillation and the SeqKD baseline. Across all datasets, GAD consistently outperforms the baselines. As shown in Figure˜1, on the LMSYS-Chat test set, Qwen2.5-3B-Instruct trained with GAD matches the performance of Qwen2.5-7B-Instruct trained with SeqKD; similarly, Qwen2.5-7B-Instruct with GAD rivals Qwen2.5-14B-Instruct with SeqKD, and Qwen2.5-14B-Instruct with GAD is comparable to the GPT-5-Chat teacher. In addition, GAD shows particularly strong gains on out-of-distribution generalization benchmarks. On Dolly, SelfInst, and Vicuna, SeqKD yields marginal or even negative improvements, whereas GAD maintains robust performance gains. We attribute this to the superior generalization ability of reinforcement learning compared to supervised fine-tuning [sftmemrlgen, dft]. We also provide additional automatic evaluation results in Section˜B.1.
Human Evaluation
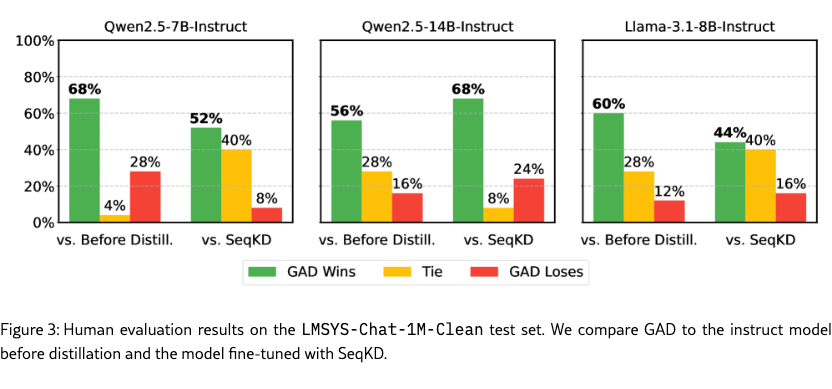
We conduct human evaluations on Qwen2.5-7B-Instruct, Qwen2.5-14B-Instruct, and Llama-3.1-8B-Instruct, comparing GAD against both the instruct model before distillation and the model fine-tuned with SeqKD. For each prompt, the annotators assess the responses of two models and judge whether GAD wins, ties, or loses. GAD achieves a win rate exceeding 50% and a loss rate below 30% in almost all comparisons. The results indicate that GAD can consistently outperform the baseline models on human evaluation performance.
3.3 Analysis
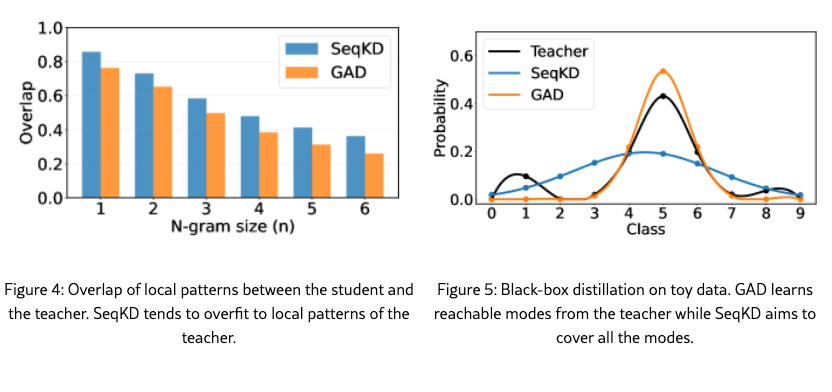
SeqKD Overfits to Local Patterns
We evaluate the similarity of local patterns between the student and teacher on the LMSYS-Chat test set in Figure˜5, measured by the F1 score of N-gram overlap. The student is trained from Qwen2.5-14B-Instruct, and the teacher is GPT-5-Chat. The SeqKD student exhibits a higher N-gram overlap while a lower GPT-4o evaluation score compared to the GAD student. This suggests that supervised fine-tuning tends to memorize local lexical patterns [sftmemrlgen, dft], whereas our RL-based approach better captures the teacher’s global stylistic characteristics.
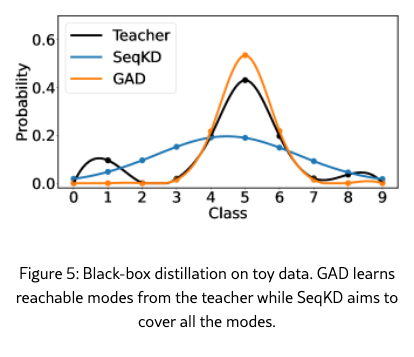
Experiments on Toy Data
We simulate the optimizing patterns of GAD and SeqKD in a toy experiment shown in Figure˜5. We observe that GAD tends to learn reachable modes of the teacher, whereas SeqKD aims to cover all modes. The setup simulates a black-box distillation scenario. We define a discrete Gaussian mixture distribution as a teacher distribution , which has categorical outputs . A student, modeled as a single Gaussian distribution, learns to imitate the teacher using only output samples without access to . We compare two student training schemes, SeqKD and GAD. The GAD student is optimized using the REINFORCE algorithm [reinforce]. As illustrated in Figure˜5, the SeqKD student exhibits a mode-covering behavior, spreading probability mass across all possible outputs [minillm]. In contrast, the GAD student focuses on mode-seeking, concentrating probability optimization on reachable regions. We find that such mode-seeking behavior leads to more effective knowledge distillation in LLMs.
Comparison to Off-Policy Discriminator
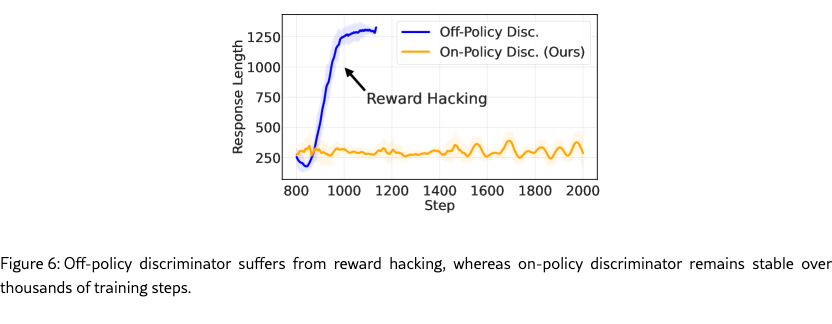
As discussed in Section˜2.1, from the view of reinforcement learning, our generator (student) acts as the policy model, while the discriminator acts as the on-policy reward model. Figure˜6 compares GAD with the off-policy discriminator approach. In the off-policy setting, the student is first trained for one warmup epoch using SeqKD. The student is then frozen, and the discriminator is trained for two epochs based on the student’s output. Then the resulting discriminator serves as a frozen reward model to train the student using Equation (7). In contrast, GAD jointly trains the student and discriminator for one warmup epoch followed by two GAD training epochs, positioning the discriminator as an on-policy reward model. We observe that the student trained with an off-policy discriminator quickly exhibits reward hacking after around 300 training steps, producing excessively long responses (up to 1300 tokens) that deviate significantly from the teacher’s patterns. In comparison, GAD remains stable through thousands of training steps with no sign of reward hacking. The results establish GAD as a highly reliable and robust on-policy distillation method.
3.4 Ablations
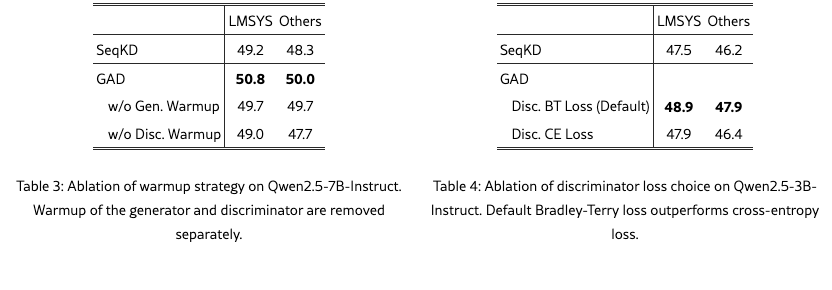
Warmup Strategy
We perform an ablation study of the warmup strategy introduced in Section˜2.2. As shown in Section˜3.4, we separately remove the warmup stage for the generator and the discriminator on Qwen2.5-7B-Instruct. When removing the generator warmup, we directly use Qwen2.5-7B-Instruct without SeqKD as initialization for both the generator and discriminator for GAD training. This leads to a performance drop. We attribute this to the discriminator easily distinguishing between the student and teacher outputs in the early training stage. The large distributional gap between the teacher and the student weakens the effectiveness of GAD training. When removing the discriminator warmup, we use the generator obtained after one epoch of SeqKD and initialize the discriminator with the original Qwen2.5-7B-Instruct. In this setting, the imbalance between the generator and the discriminator prevents the discriminator from providing sufficiently informative feedback. Consequently, the adversarial interaction becomes ineffective, and the generator exhibits little improvement beyond its warmup performance.
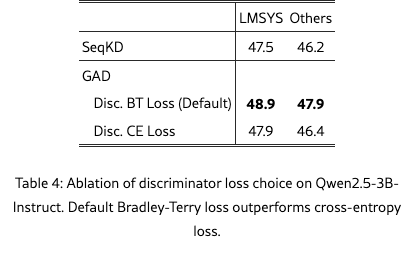
Discriminator Loss Choice
We ablate the choice of discriminator loss in Section˜3.4, and observe that our default Bradley-Terry loss outperforms cross-entropy loss in overall GPT-4o evaluation score. The Bradley-Terry loss is defined in Equation (3), while the cross-entropy loss is a binary classification loss commonly adopted for discriminator in prior works [gan, seqgan, GAIL, learningdense]. The cross-entropy discriminator loss can be written as:
| (4) |
Experiments on Qwen2.5-3B-Instruct shows that Bradley-Terry loss can enhance discriminator training stability and improve automatic evaluation scores over cross-entropy loss. The result highlights the effectiveness of Bradley-Terry loss for discriminator training in LLMs.
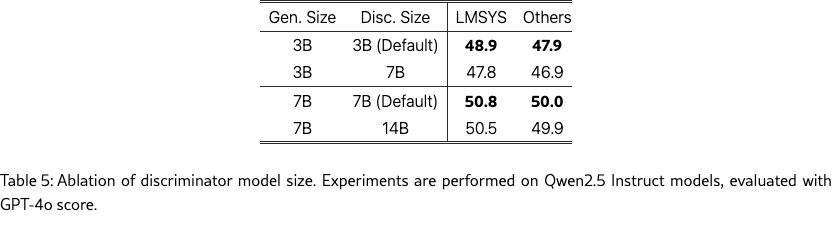
Discriminator Model Size
We ablate the relative model size of the generator and discriminator in Table˜5. Using equal model sizes for the two models, which is our default setting, yields the best performance. The experiments are conducted on Qwen2.5 Instruct models and evaluated by GPT-4o scores. We increase the discriminator model size from 3B to 7B for the 3B student, and from 7B to 14B for the 7B student in GAD. Increasing the discriminator size does not improve performance. The experiment shows maintaining a balanced generator-discriminator pair is crucial for achieving strong performance.
4 Related Work
White-box Distillation of LLM
White-box knowledge distillation of LLM assumes full access to the internal representations or token-level probabilities of a teacher model. Standard white-box approaches align the forward KLD of distribution [mixkd, lightpaff], reverse KLD of distribution [minillm], hidden states [tinybert, bert-pkd] or attention scores [minilm, minilmv2] between the teacher and the student. Recent work [minillm, thinkingmachine-onpolicy, googlepolicy] also proves the importance of on-policy distillation where the student learns from its own responses. Such approaches effectively compress large models while preserving semantic similarity. Despite their effectiveness, these methods rely on full teacher access, which is impractical for proprietary LLMs and limits their applicability to closed-source or API-only teachers.
Black-box Distillation of LLM
Black-box distillation trains a student model using only the textual outputs of a teacher, typically obtained by API queries to closed-source models such as GPT-5 and Gemini 2.5 [gpt5, gemini2d5]. In this setting, conventional white-box distillation methods become infeasible because of the lack of access to the teacher’s logits or hidden representations. The standard approach for this scenario, SeqKD, performs supervised fine-tuning (SFT) on the teacher’s responses [skd, ITGPT4, lima, alpaca, vicuna] to imitate the teacher’s behaviors. Recent work [s1, openthoughts, limo, deepseekr1] extends this paradigm by performing SFT on the teacher’s reasoning traces to improve the student’s reasoning ability.
5 Conclusion
We introduce GAD, a generative adversarial framework that effectively addresses key challenges of black-box LLM distillation. GAD enables on-policy learning by training a student model and an adaptive discriminator in a minimax game, eliminating the need for any logit-level supervision. This discriminator provides an implicit, on-policy reward signal that guides the student’s optimization. Experiments across multiple model families and datasets confirm our approach. GAD consistently surpasses standard sequence-level distillation, delivering superior generalization and achieving performance that rivals the proprietary teacher. These results validate GAD as an effective and robust solution for black-box LLM distillation.
Acknowledgements
We are grateful to Yi Zhu for technical support during the development of the RL infrastructure and to Yuxian Gu for insightful discussions.
Appendix A Experimental Details
A.1 Implement GAD with GRPO
We implement policy optimization of the student with GRPO [grpo]. We use to denote the output distribution of student . For each input prompt , we sample a group of student responses , and obtain their corresponding rewards , where . The advantage of the -th response can be calculated with:
| (5) | ||||
| (6) |
The student is trained with the following objective:
| (7) |
where we omit the KL regularizer and the clip operator in GRPO for brevity.
For the discriminator, we pair each student response in the group with the same teacher response to form preference pairs. The discriminator parameters are optimized by minimizing the Bradley-Terry loss across the group:
| (8) |
where is the teacher score shared within the group.
A.2 Training Details
We train all models with 3 epochs. For GAD, the training consists of 1 warmup epoch followed by 2 GAD training epochs. The models are trained with a batch size of 256, totaling approximately 2400 optimization steps. The PPO mini-batch size for each policy update is also 256. In the warmup stage of GAD, we train the discriminator for 10 steps before jointly training the generator and discriminator.
We search learning rate in [1e-6, 5e-6] for GAD and SeqKD baseline. For SeqKD, we find 5e-6 leads to better results in all experiments. For GAD with GPT-5-Chat teacher, we use 1e-6 for both warmup and GAD training stage, and for GAD with Qwen2.5 teacher as in Table˜7, we use 5e-6 for warmup stage and 1e-6 for GAD training stage. The maximum context length is set to 2048 tokens for instruction prompts and 1536 for model responses. The training temperature is set to .
In the GRPO algorithm formulated as Equation (7), we set group size and the KL weight .
Distilling Qwen2.5-14B-Instruct from GPT-5-Chat takes about 30 hours on 16 H100 GPUs.
A.3 Automatic Evaluation Details
The sampling temperature is set to and model response length is set to 1536 tokens, same as in training. We use the prompt wrapper in Figure 7 to construct prompts. We use the prompt in Figure 8 for GPT-4o feedback following [minillm].


Appendix B Additional Results
B.1 Additional Automatic Evaluation Results
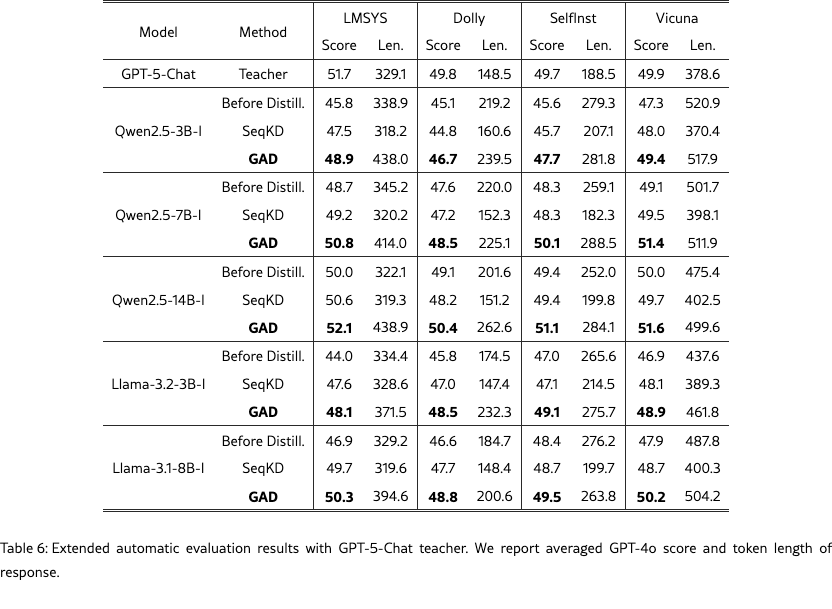
GPT-5 Teacher
We provide additional results of the automatic evaluation. In Table˜6, we report GPT-4o score and response lengths of distilled student models trained with the GPT-5-Chat teacher. Across datasets, we observe that SeqKD tends to produce shorter responses that closely follow the teacher’s length distribution whereas GAD maintains the original model’s length distribution while integrating the teacher’s global stylistic characteristics. We attribute this behavior to the on-policy sampling of GAD, which encourages generation patterns aligned with both the student’s prior and the teacher’s guidance.
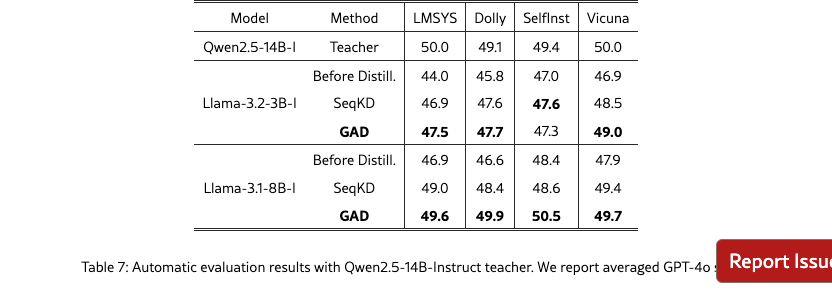
Qwen2.5 Teacher
In Table˜7, we distill from Qwen2.5-14B-Instruct teacher to student models from the Llama family. Although the teacher is open-source, its tokenizer is incompatible with the students, preventing direct application of white-box distillation methods that align KL divergence between teacher and student logits. In this setting, GAD remains effective, outperforming both the pre-distillation models and the SeqKD baseline in most settings on GPT-4o evaluation score.