Attribute-Aware Controlled Product Generation with LLMs for E-commerce
Abstract
Product information extraction is crucial for e-commerce services, but obtaining high-quality labeled datasets remains challenging. We present a systematic approach for generating synthetic e-commerce product data using Large Language Models (LLMs), introducing a controlled modification framework with three strategies: attribute-preserving modification, controlled negative example generation, and systematic attribute removal. Using a state-of-the-art LLM with attribute-aware prompts, we enforce store constraints while maintaining product coherence. Human evaluation of 2000 synthetic products demonstrates high effectiveness, with 99.6% rated as natural, 96.5% containing valid attribute values, and over 90% showing consistent attribute usage. On the public MAVE dataset, our synthetic data achieves 60.5% accuracy, performing on par with real training data (60.8%) and significantly improving upon the 13.4% zero-shot baseline. Hybrid configurations combining synthetic and real data further improve performance, reaching 68.8% accuracy. Our framework provides a practical solution for augmenting e-commerce datasets, particularly valuable for low-resource scenarios.
Attribute-Aware Controlled Product Generation with LLMs for E-commerce
Virginia Negri1 Víctor Martínez Gómez1 Sergio A. Balanya1 Subburam Rajaram2 1Amazon Spain 2Amazon Germany {vrgngr, vicmg, sbalanya}@amazon.es, subburb@amazon.de
1 Introduction
In e-commerce services, high-quality product information is fundamental to customer experience, powering critical features like search, filtering, and recommendations 10.1145/2487575.2488217. However, major online stores frequently encounter noisy or inaccurate product details gao2019productawareanswergenerationecommerce, making manual curation impractical at scale. The development of automated product information systems is hindered by the scarcity of diverse, high-quality training datasets. These datasets must capture the intricate relationship between structured attributes and their various representations in product text fields. For example, a "waterproof" attribute might be expressed as "water-resistant material," "keeps you dry in rain," or "weatherproof construction" across different text fields. Traditional manual annotation is expensive and struggles to capture this full spectrum of variations and edge cases.
Recent advances in Large Language Models (LLMs) offer promising solutions for generating synthetic training data. While LLMs have been successfully applied to various text generation tasks, to our knowledge, this is the first work that specifically addresses the comprehensive generation of synthetic product information in e-commerce.
We present a novel approach that leverages LLMs to generate synthetic product data through controlled modification of existing product information. Our framework implements three strategies: (1) correct attribute modification, (2) controlled generation of negative examples, and (3) systematic attribute removal. Through a sophisticated multi-step validation process using specialized LLMs, we ensure both attribute validity and semantic coherence across all product fields while preserving category-specific characteristics.
The key innovation lies in our comprehensive generation framework that handles edge cases, maintains structural consistency, and provides carefully designed prompt components that enforce marketplace-specific constraints. Our system supports multi-lingual generation, adapts to different marketplace requirements, and implements systematic brand anonymization to prevent unwanted biases. Unlike previous approaches that focus on single-aspect generation tasks chan-etal-2019-stick, our method creates complete, coherent product information while maintaining realistic market context.
In the following sections, we detail our methodology, present experimental results through human evaluation, and discuss implications for e-commerce systems. Our work provides a practical framework for generating large-scale synthetic datasets that advance the development of robust product information systems.
2 Related Work
Synthetic data has emerged as a promising solution to generate large-scale datasets that resemble real-world data liu2024bestpracticeslessonslearned. While synthetic data generation has been explored across various domains bauer2024comprehensiveexplorationsyntheticdata, its application to e-commerce presents unique challenges due to the intricate relationship between structured attributes and their representation in text fields. Studies have shown that maintaining product data quality is costly: large e-commerce services spend an average of $12.9 million annually on content quality assurance effortsgartner2021improvedataquality. Traditional data generation approaches include custom algorithms saxton2019analysingmathematicalreasoningabilities, generative models borisov2023languagemodelsrealistictabular, and data augmentation techniques like back-translation sennrich2016improvingneuralmachinetranslation and rule-based transformations pluščec2023dataaugmentationneuralnlp. However, these methods often produce limited variations and may not maintain domain-specific characteristics.
In e-commerce, previous work has explored approaches similar to ours for maintaining attribute fidelity in generated product content. FPDG chan-etal-2019-stick uses entity-label guidance and specialized architectures to generate faithful product descriptions. While effective, this approach requires explicit entity labeling and relies on architectural constraints rather than semantic understanding, limiting its adaptability to new domains and edge cases. In contrast, our approach leverages LLMs’ broader semantic understanding to handle various scenarios including attribute removal and controlled inconsistencies.
Recent advances in LLMs have expanded synthetic data generation capabilities, demonstrating remarkable zero-shot and few-shot abilities brown2020languagemodelsfewshotlearners while maintaining domain-specific characteristics when properly constrained ding2023gpt3gooddataannotator. Our work builds on these capabilities to create diverse, balanced datasets with controlled attribute distributions and brand anonymization, addressing the challenges of data scarcity and quality in e-commerce.
3 Methodology
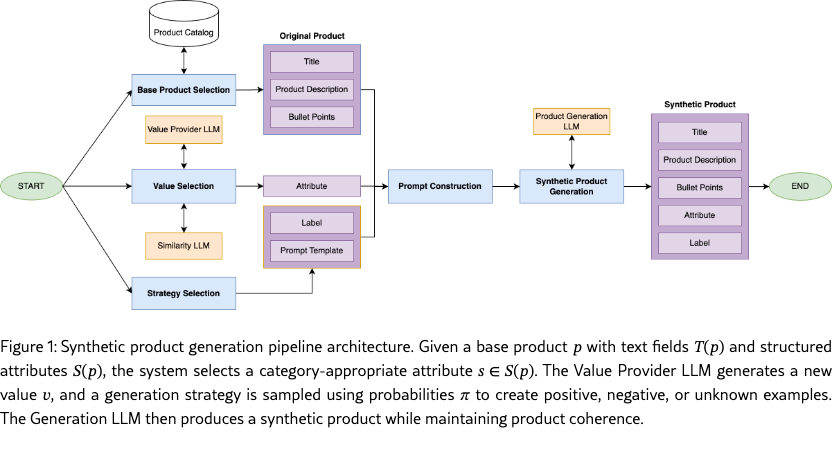
Our approach generates synthetic e-commerce products through controlled modification of existing product data, ensuring the generated information maintains realistic characteristics while providing precise control over attribute modifications.We leverage LLMs to perform these modifications systematically, preserving structural consistency and semantic coherence throughout the product description.
3.1 Data Representation
A product in the catalog is defined by its structured attributes and text fields . The structured attributes consist of key-value pairs where values are typically constrained to a predefined set of options (e.g., {color: "red", size: "medium"}). These are called structured because they follow a rigid format: values are usually single words or short phrases chosen from a fixed vocabulary, making them easily extractable and analyzable. In contrast, the text fields contain free-form natural language content, such as a product’s title, description, and so on. Our generation pipeline takes as input a base product and selects a structured attribute that is relevant for that product’s category (e.g., "heel height" for shoes, "material" for clothing).
3.2 Attribute Value Generation
The generation of new attribute values requires careful consideration of both attribute constraints and semantic relationships. We employ two complementary approaches depending on the generation strategy.
For positive examples and attribute removal cases, we use a Value Provider LLM that considers product category specifications, marketplace requirements, and previously used values to ensure diversity. When attribute metadata is available (e.g., data type, valid units), it is used to constrain and validate the generated values. Otherwise, the Value Provider LLM leverages its prior knowledge, guided by carefully designed prompts, to determine appropriate units, ranges, and formats for the attribute values.
For negative examples, we employ a two-step process: first generating a pool of valid values using the Value Provider LLM (with temperature for diversity), then using a Similarity LLM to select values that are semantically distinct from the correct value, avoiding synonyms or closely related concepts.
3.3 Product Generation Strategies
Our system implements three distinct product generation strategies that reflect common scenarios in real e-commerce data:
-
1.
Positive Example Generation (, ): Creates examples where the structured attribute value is correctly reflected in the product text fields. Given a new value for attribute , an LLM modifies all references to in to maintain consistency with while preserving the original text structure. For example, if modifying the color attribute from "red" to "blue", all mentions of "red" in the title, description, and bullet points are updated accordingly.
-
2.
Negative Example Generation (, ): Introduces controlled inconsistencies between structured attributes and text fields, mimicking real-world data quality issues. An LLM introduces a single, subtle reference to an incorrect value while maintaining the correct value as the primary attribute. For instance, it might modify "Perfect for summer hiking" to "Perfect for summer hiking, though not as warm as winter boots" when generating a negative example for the season attribute.
-
3.
Incomplete Example Generation (, ): Removes all references to the target attribute while preserving product coherence, simulating cases where attribute values cannot be inferred from product text. This strategy is particularly valuable for training extraction models to handle missing information scenarios.
These strategies, with their respective probabilities , can be adjusted to match real-world distributions or specific application needs. The diverse set of examples helps train more robust attribute extraction models by exposing them to both ideal and challenging scenarios commonly found in e-commerce data.
3.4 Prompt Design
Our system uses a carefully crafted prompt template with four key components:
-
•
Role Definition: Establishes the LLM as an e-commerce product expert.
-
•
Task Instructions: Specifies the generation requirements including brand anonymization, structure preservation, and attribute consistency rules.
-
•
Product Context: Provides the base product’s text fields and the target attribute modification details.
-
•
Output Format: Defines a JSON structure for standardized responses.
These components work together to enforce critical constraints: replacing existing brands with plausible fictional alternatives (e.g., changing a popular sport brand into "AthleteX") to prevent data leakage and brand-specific biases, maintaining the original text structure, ensuring coherent attribute modifications across all text fields, and respecting store-specific formats (e.g., imperial units in US store listings).
| (1) |
3.5 Generation Process
The generation process follows Algorithm 1. First, the product category is identified to guide attribute selection. Then, a relevant structured attribute is chosen from those available for that category (e.g., "heel height" for shoes). A generation strategy is sampled according to the predefined probabilities . Based on the selected strategy and category constraints, a new attribute value is generated (e.g., ensuring appropriate units or value ranges). Finally, the LLM modifies the product using our carefully designed prompt, which ensures all constraints are maintained in a single generation step.

3.6 Implementation
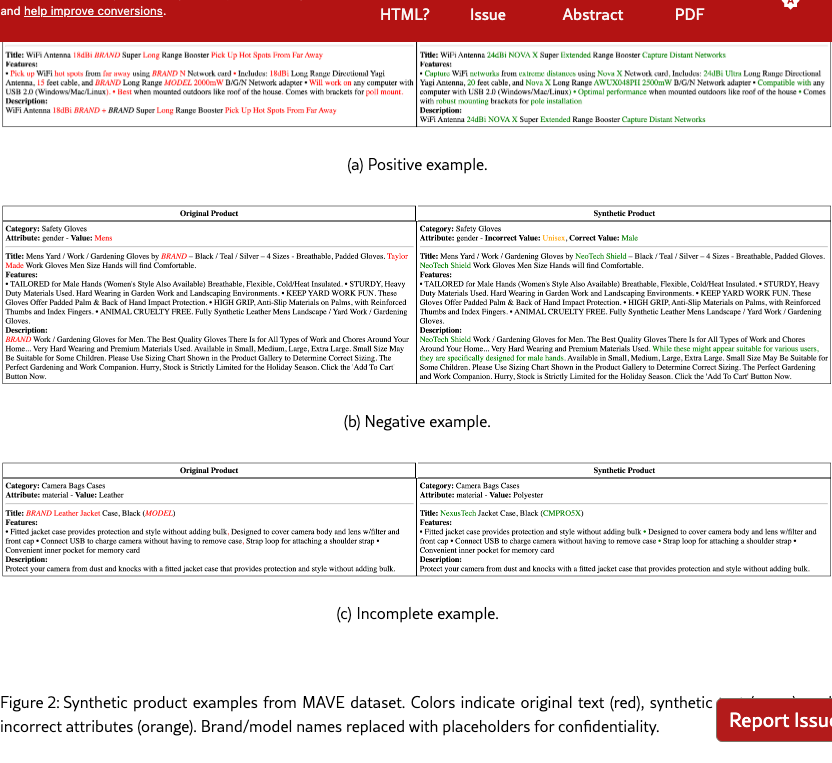
Our system is implemented in Python using (1) the same LLM 111We use Claude Haiku TheC3 for both the Value Provider and generation components, and (2) a sentence-transformers model 222The sentence transformer model is available at https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 under the Apache 2.0 license. for the Similarity LLM reimers2019sentencebertsentenceembeddingsusing. Figure 2 shows an example of the generated output, highlighting the modifications made to the original product.


4 Experimental Setup
4.1 Dataset and Sampling
We evaluate our approach using MAVEyang2021maveproductdatasetmultisource, a large-scale product attribute dataset with 2.2 million products across 1,257 categories. We consolidated each product’s textual information into title, description, and features fields, while maintaining attribute-value pairs and their text spans. From this dataset, we sampled 2,000 products from the top 200 categories, with one randomly selected attribute per product. For each product we take it’s textual information, the attribute’s value and the category. We generated synthetic versions using three strategies with controlled probabilities: correct attribute modification (50%), incorrect examples (25%), and unknown attributes (25%). Detailed dataset statistics and category distributions are provided in Appendix A.
4.2 Human Evaluation
We conducted a comprehensive evaluation of our synthetic products using expert human annotators with e-commerce domain experience. Our evaluation is exhaustive, covering all three generation strategies: correct attribute modifications, incorrect attribute examples, and unknown attribute cases. We collected three labels per product by three independent annotators, with final decisions made by majority voting. Each annotator was shown pairs of original and synthetic products with highlighted modifications (detailed protocol in Appendix F) and asked to evaluate six key aspects:
-
1.
Attribute Value Quality: Appropriateness of the generated value for the product category and attribute type
-
2.
Negative Example Coherence: For negative cases, plausibility of both the correct and incorrect values in the context
-
3.
Cross-field Consistency: Coherent representation of the attribute value across title, description, and features
-
4.
Brand Modification: Effectiveness of brand name replacements and consistency throughout the text
-
5.
Content Preservation: Assessment of any unintended changes beyond the target modifications
-
6.
Professional Writing: Overall text quality and maintenance of e-commerce writing standards
4.3 Downstream Task Evaluation
To evaluate our synthetic data quality, we assess its effectiveness in attribute value extraction, a crucial e-commerce task. We focus on correct examples to enable direct comparison with the original dataset, comparing models trained on various combinations of synthetic and original data. Results demonstrate that our generated examples match the quality of real training data.
Models and Input Processing. We implemented attribute extraction using FLAN-T5-base333FLAN-T5 is available at https://huggingface.co/google/flan-t5-base under the Apache 2.0 license. 10.5555/3722577.3722647, processing the product’s text fields (title, description and features) in a structured prompt template with a 512-token context window. The task is framed as a generation problem, allowing for free-form attribute value prediction.
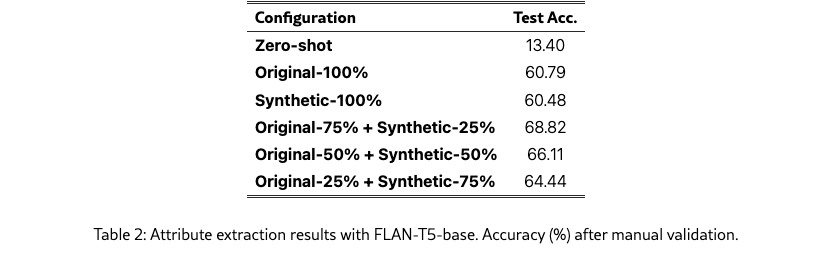
Dataset Configuration. From our sampled products, we utilized correct examples (800 products) for training (80%) and validation (20%), evaluating on the remaining products (1,000). We tested six configurations: zero-shot evaluation, original data only, synthetic data only, and three hybrid configurations combining original and synthetic data in different proportions (75/25, 50/50, and 25/75 splits).
Training Setup. We fine-tuned the model using AdamW optimizer (learning rate=5e-5) for up to 12 epochs with early stopping on validation accuracy. For generation, we used beam search (beams=5) with controlled sampling (temperature=0.7, top_k=50, top_p=0.95) and length constraints (max_length=20) to ensure diverse yet accurate outputs.
5 Results and Analysis
5.1 Human Evaluation
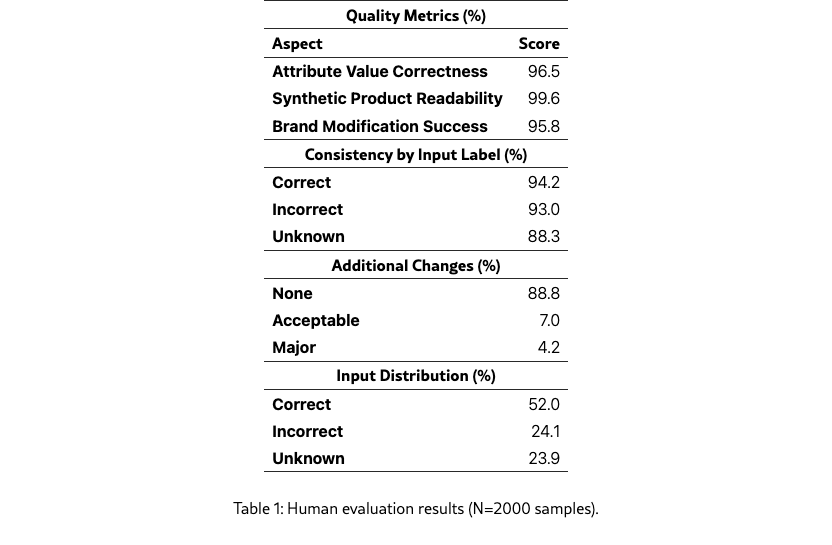
Our human evaluation of 2,000 synthetic products demonstrates strong performance across key quality metrics (Table 1). Expert reviewers rated 99.6% of products as having natural e-commerce language and 96.5% as containing valid attribute values. Brand anonymization was correctly implemented in 95.8% of cases. Attribute consistency was maintained across all generation types: 94.2% of products remained consistent when we modified their correct attributes, 93.0% when we deliberately introduced incorrect values, and 88.3% when we strategically removed attributes from the text fields. The evaluation showed that 88.8% of products preserved their original structure completely, with 7.0% showing minor acceptable changes and 4.2% requiring significant revisions, primarily in cases with empty descriptions. Quantitative analysis of edge cases showed that the model successfully generated appropriate content for all empty descriptions (100% of 47 cases) and correctly anonymized brand names in 95.8% of products without explicit instructions. Manual analysis identified that validity and consistency errors primarily originated from issues in the source dataset, specifically overly generic attribute values (e.g., "type") and semantically misaligned attributes. A manual inspection of a small sample of the synthetic data hints to the model’s ability of generating more precise and standardized attribute values compared to the original data. Future improvements could focus on implementing clearer attribute definitions, enhanced handling of semantically misaligned values, and additional validation prompts for brand handling.
5.2 Impact on Attribute Extraction Models
Our experiments demonstrate that synthetic data has comparable performance on real data in attribute extraction (Table 2). Training with synthetic data alone achieves 60.48% accuracy on our test set, performing on par with the original data (60.79%) and substantially improving upon the zero-shot baseline of 13.4%. This comparable performance indicates our synthetic data captures the essential patterns without introducing noise. Hybrid configurations yield even better results, with the 75%-25% original-synthetic mix reaching 68.82% accuracy. Performance gradually decreases by 2.71 and 4.38 percentage points as we increase the synthetic portion to 50% and 75% respectively, suggesting an optimal mixing ratio. Manual review of the test predictions initially marked as incorrect (441 out of 959 examples for the synthetic only configuration) revealed that many model outputs were semantically correct but differed from MAVE’s annotations in format. We identified seven types of valid variations: (1) granularity differences (e.g., “running shoe” vs “running”), (2) morphological variations (“wall sticker” vs “wall stickers”), (3) multiple valid values (“t-shirt” or “tank top” for the same product), (4) missing units (“1200” vs “1200 thread count”), (5) equivalent attribute definitions (“type=processor” vs “type=food processor”), (6) contextual synonyms (“striped” vs “stripe”), and (7) format variations (“ipod touch” vs “for apple ipod”). These findings highlight both the quality of our synthetic data generation pipeline and the inherent complexity of maintaining consistent attribute value annotations in product catalogs.
6 Conclusions
We presented a novel approach to generate synthetic e-commerce product data at scale using LLMs, using existing products as reference templates. Expert evaluation of 2,000 synthetic products demonstrates high effectiveness: 99.6% natural-sounding content, 96.5% valid attribute values, and over 90% consistent attribute usage. In downstream attribute extraction, our synthetic data matches the performance of real training data (60.5% vs 60.8% accuracy) while significantly improving upon the 13.4% zero-shot baseline, with hybrid approaches reaching 68.8% accuracy. Our framework enables rapid generation of high-quality training data that has comparable performance to real data, providing a scalable solution for bootstrapping e-commerce services when labeled data is scarce.
Limitations
Our work contains some limitations that suggest directions for future research. First, while our synthetic data has comparable performance to real data in attribute extraction, we only evaluated on positive examples. Future work should investigate how models trained with our synthetic data, including incorrect and unknown attributes, perform on more diverse downstream tasks.
Third, while 88.8% of products maintain their structure with no unintended changes, future work could explore stronger controls over modifications beyond the target attribute. This is particularly important for hybrid training scenarios, where maintaining high-quality synthetic data is crucial for complementing real data effectively. Fourth, our current implementation focuses on single attribute modifications; future work will explore extending to multiple attributes while ensuring consistent interaction between modified attributes, potentially improving the utility of synthetic data in downstream tasks.
Additionally, the quality of our synthetic data depends heavily on the input product descriptions, which can contain problematic patterns such as vague attributes (e.g., "shoes" as a "type" value for shoe products), missing information (e.g., absent brand mentions), or inconsistent attribute definitions (e.g., confusing "style" with "pattern"). Although our generation process often improves upon these issues by producing more precise values and complete descriptions, this improvement complicates evaluation since the synthetic data might deviate from the original while being more accurate.
A key area for future work is developing stronger constraints on attribute value generation. Our manual review revealed variations in granularity (e.g., "running shoe" vs "running") and distribution of values between original and synthetic data. Future research should explore methods to enforce consistent granularity levels and maintain similar value distributions across the dataset, possibly through attribute-specific vocabularies or controlled generation techniques. This would ensure more standardized attribute values while preserving the semantic richness of the synthetic data.
Finally, while hybrid configurations show superior performance (68.8%), future work should investigate methods to better understand and exploit the complementary strengths of synthetic and real data. This includes developing improved integration methods and exploring how different mixing ratios affect specific attribute types or product categories.
Responsible AI Considerations
Bias Mitigation: Brand anonymization (95.8% success) prevents brand-specific biases from propagating. However, source data biases in attribute distributions may persist. Future work should examine demographic representation and implement debiasing strategies.
Quality Governance: Our multi-stage validation (Value Provider Generation Semantic Validation) provides quality controls, but 4.2% of products showed major unintended changes, primarily from empty source descriptions. However, manual audits of a small sample revealed the changes did not affect the overall synthetic productś quality.
Fairness Implications: Our framework generates more standardized attributes than source data, potentially improving fairness by reducing inconsistent descriptions.
Appendix A Dataset Statistics
The MAVE dataset yang2021maveproductdatasetmultisource is a large-scale product attribute dataset containing over 3.3 million products across 1,212 categories, with 662 unique attributes. The dataset includes both positive examples (2.1M products) where attributes are present in the text, and negative examples (1.1M products) where attributes are mentioned but not present in the product text. On average, each product contains 1.38 attributes. For our experiments, we sampled 2,000 products from the top 200 categories, ensuring broad coverage while maintaining manageable evaluation size. Our sampling strategy preserved the natural distribution of attributes within categories while ensuring sufficient representation of different attribute types.
A.1 Basic Statistics
The dataset consists of product listings from various categories, with each product containing structured information including:
-
•
Product id
-
•
Category
-
•
Description
-
•
Features: Single sentences describing a feature of the product
-
•
Attribute-value pairs with supporting evidence
A.2 Data Distribution
A.2.1 Category Distribution
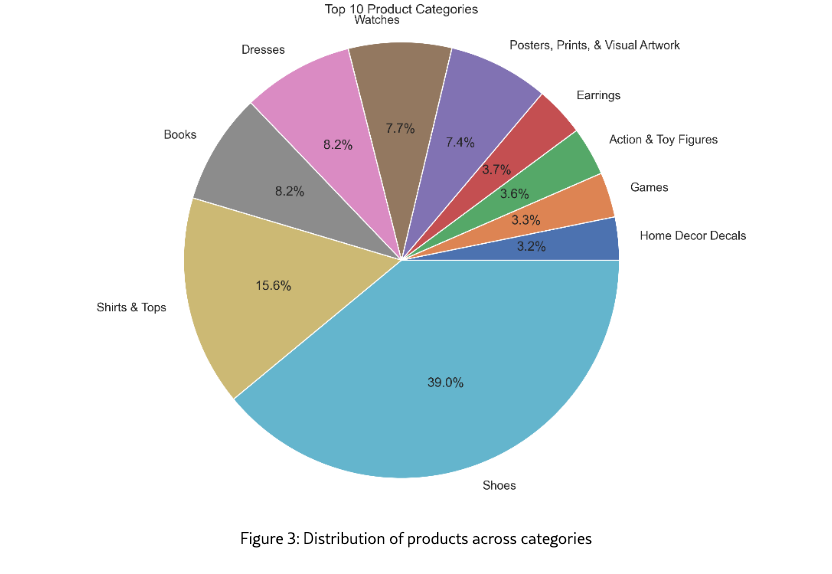
Figure 3 shows the distribution of products across different categories. The dataset covers a wide range of product categories, with Shoes, Shirts & Tops and Books being the most prevalent. This diversity ensures that our findings are generalizable across different product types.
A.3 Attribute Coverage
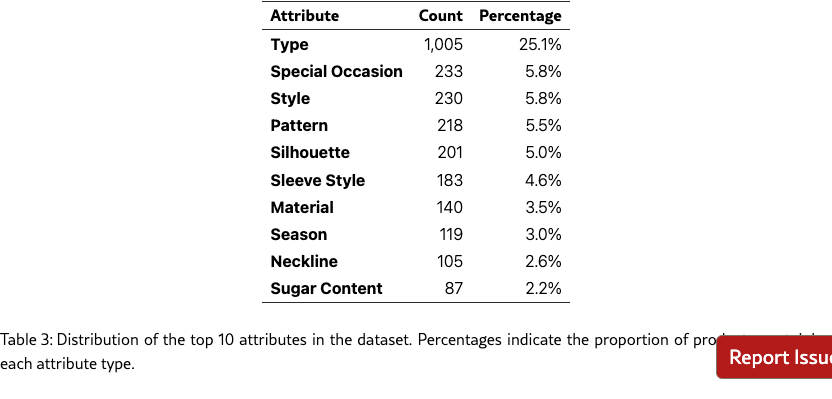
Products are annotated with various attributes, with evidence spans marked in the text. As shown in Table 3, the most prevalent attribute is "Type" (25.1% of products), followed by "Special Occasion" and "Style" (both 5.8%). The top 10 attributes account for 63.1% of all attribute annotations, indicating a long-tail distribution of attribute types in the dataset. This distribution reflects the diverse nature of product descriptions, where certain fundamental attributes (like Type) are nearly universal, while others are more category-specific.
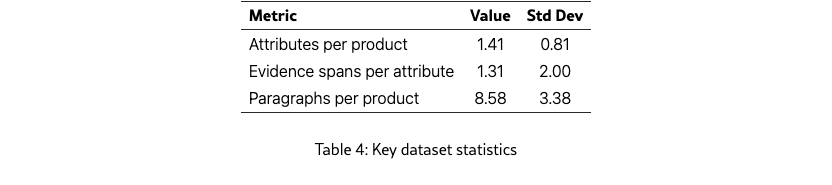
Key statistics of our attribute annotation include:
-
•
Average number of attributes per product: 1.41
-
•
Average number of evidence spans per attribute: 1.31
Notably, attributes like "Sugar Content" (2.2%) appear in the top 10 despite being category-specific, suggesting a significant presence of food and beverage products in our dataset. The presence of clothing-related attributes such as "Silhouette" (5.0%), "Sleeve Style" (4.6%), and "Neckline" (2.6%) indicates a substantial representation of fashion items.
A.4 Evidence Distribution
The evidence spans for attributes are distributed across different paragraph sources:
-
•
Title: 11.7% of evidence spans
-
•
Description: 15.3% of evidence spans
-
•
Features: 57.9% of evidence spans
-
•
Brand: 10.0% of evidence spans
-
•
Price: 5.1% of evidence spans
This distribution shows that attribute information is spread across different parts of the product listing, highlighting the importance of considering all textual content for attribute extraction.
A.5 Data Quality
To ensure data quality, we analyzed:
-
•
Completeness: All products have at least one attribute
-
•
Consistency: Attribute values are supported by textual evidence
-
•
Coverage: Evidence spans are properly annotated and linked to attributes
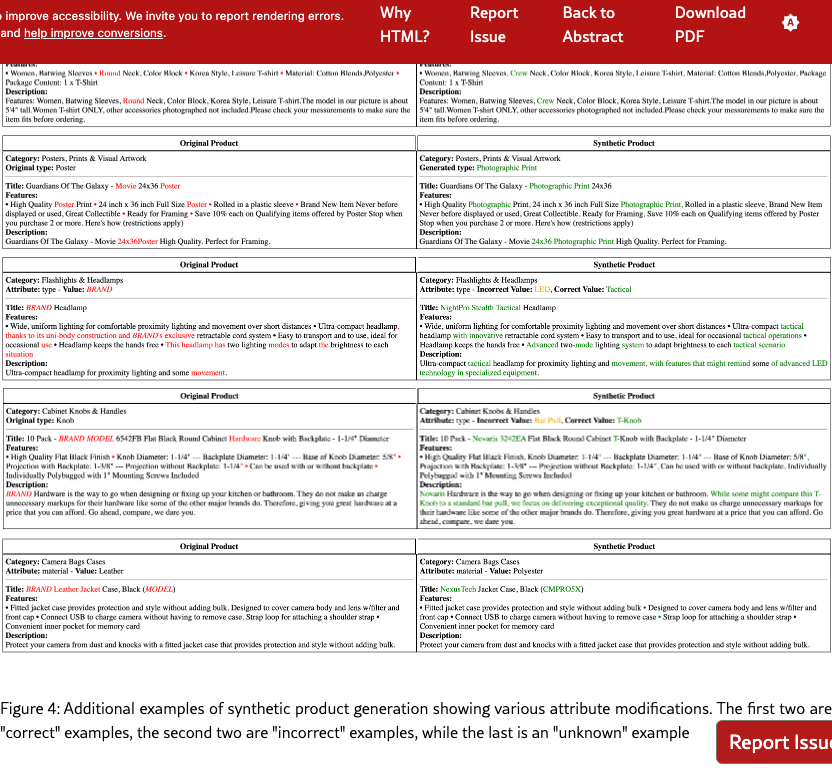
Appendix B Additional Examples of Synthetic Product Generation
In Figure 4 we find 5 examples of synthetic products generated from products in the benchmarking dataset. Changes are highlighted in red (original text), green (synthetic text), and orange (incorrect attributes in the synthetic product) to illustrate different types of modifications and their propagation through product descriptions.
Appendix C Error Analysis
Manual review of 441 predictions initially marked as incorrect revealed that many model outputs were semantically correct but differed from MAVE’s annotations in format or granularity. We identified seven types of valid variations:
Granularity differences: Model predicted broader or narrower terms than the gold label (e.g., “running” vs “running shoe”). Both are semantically correct but differ in specificity level.
Morphological variations: Singular vs plural forms (“wall sticker” vs “wall stickers”), both acceptable in e-commerce contexts.
Multiple valid values: Products genuinely having multiple acceptable attribute values (e.g., a garment could validly be described as “t-shirt” or “tank top”).
Missing units: Model predicted numeric value correctly but omitted units (“1200” vs “1200 thread count”). The core information is correct, only formatting differs.
Equivalent definitions: Different but equivalent attribute descriptions (“type=processor” vs “type=food processor”).
Contextual synonyms: Semantically equivalent terms in the product context (“striped” vs “stripe”, “waterproof” vs “water-resistant”).
Format variations: Different formatting conventions (“ipod touch” vs “for apple ipod”, “2.5 inch” vs “2.5in”).
These findings highlight both the quality of our synthetic data generation pipeline and the inherent complexity of maintaining consistent attribute value annotations in product catalogs. A systematic categorization of all 441 cases would require additional annotation effort, but qualitative review suggests these variations account for a substantial portion of apparent errors.
Interdependent Attributes: When modifying a beverage product from “vanilla from Madagascar” to “chocolate,” the system automatically updated the origin to “Switzerland” without explicit instruction, demonstrating semantic understanding of attribute relationships.
Precision Improvements:
-
•
SHOES category: “type=shoes” “type=running” (informative vs circular)
-
•
RIBBONS_TRIM: “type=Ribbon” “type=Satin” (material-specific)
Semantic Alignment:
-
•
SPEAKERS: “style=Bookshelf” (format) “style=minimalist” (actual style)
-
•
CLOTHING: “pattern=casual” (style) “pattern=floral” (actual pattern)
These examples demonstrate the LLM’s ability to infer appropriate attribute meanings from product category context, understanding that attributes like “style” and “type” have different semantic ranges across categories.
Appendix D Cost-Effectiveness and Scalability
Our implementation requires two LLM calls per synthetic product: a (i) Value Provider call that requires on average 402 input tokens and 10 output tokens, and (ii) a generation call with strategy-specific prompts plus product data adding an additional 1,480-1,600 input tokens, and around 141 output tokens. Using Claude Haiku’s published pricing ($0.80/million input tokens, $4.00/million output tokens), this approach is remarkably cost-effective compared to human annotation costs of approximately $0.11 per 50 tokens wang2021want. Generation completes in hours rather than weeks, enabling rapid dataset bootstrapping for new categories or markets. We verified scalability by successfully regenerating the complete MAVE dataset.
Appendix E Quantitative Metrics Details
Type-Token Ratio (TTR) by text field:
-
•
Title: Original 0.89, Synthetic 0.88
-
•
Description: Original 0.82, Synthetic 0.81
-
•
Features: Original 0.85, Synthetic 0.84
Semantic Similarity (Cosine) by text field:
-
•
Title: 0.84
-
•
Description: 0.85
-
•
Features: 0.93
KL Divergence by text field:
-
•
Title: 1.12 (higher due to attribute prominence)
-
•
Description: 0.71
-
•
Features: 0.24 (lower as attributes less prominent)
These metrics confirm targeted modifications: higher divergence in title where attributes appear prominently, lower in features where attributes are one of many product aspects discussed.
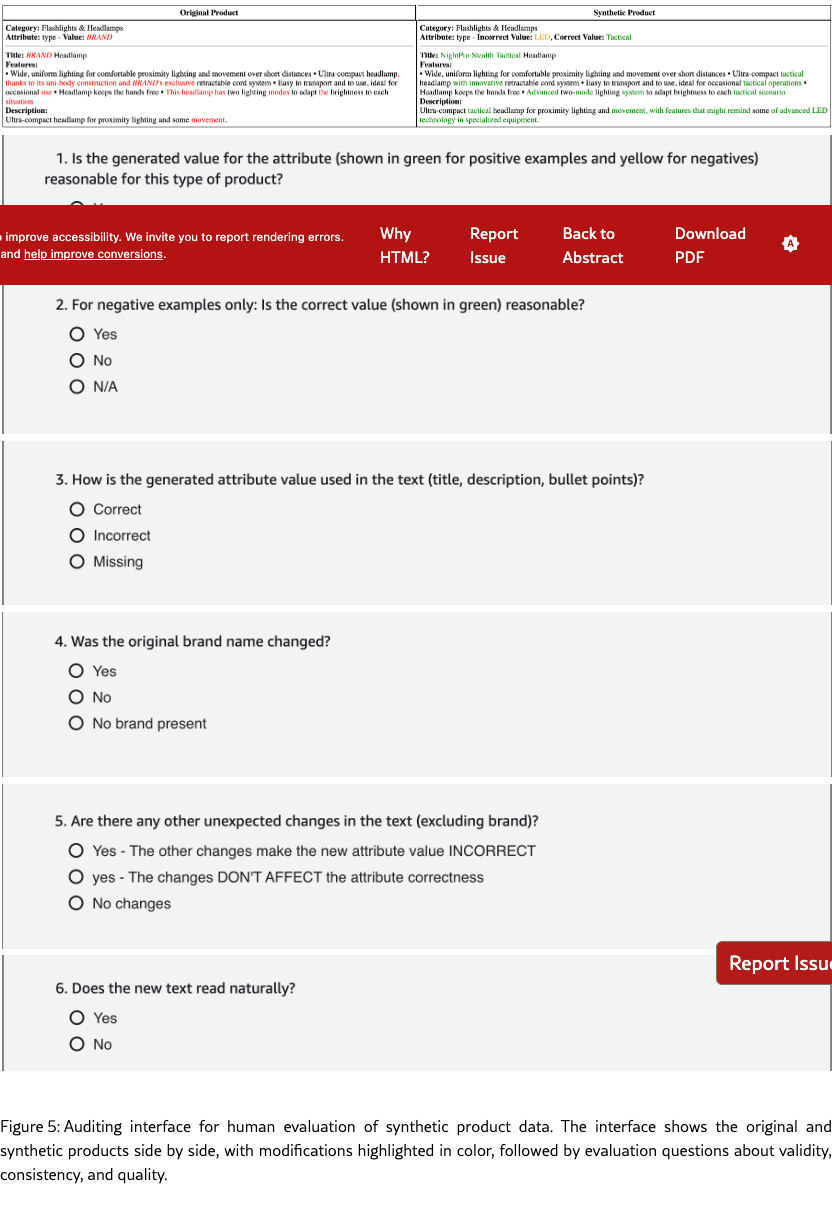
Appendix F Human Annotation Interface
Figure 5 shows the questions shared on the annotation platform to audit our data. Prior to the questions, annotators were showed a general description of the task which we share below:
You will be shown two product listings: an original and a synthetic version where one attribute has been modified.
This task includes both POSITIVE, NEGATIVE and UNKNOWN examples:
-
•
In POSITIVE examples, the modified attribute is correctly changed and consistent
-
•
In NEGATIVE examples, you’ll see both the CORRECT and WRONG (generated) values - your task is to identify if the synthetic version contains the generated wrong value consistently
-
•
In UNKNOWN examples, the text fields should have no mention about the attribute value
Please carefully review:
-
•
If the synthetic version uses the correct attribute value. Note that this can be the same or similar to the original one.
-
•
How this value appears in title, description, and bullet points
-
•
If unknown examples have all mentions of the attribute value remove
-
•
Any other changes or inconsistencies
-
•
Overall product realism
In Figure 5 we find the interface shown to human workers labeling our synthetic data. The interface first displays the original and the synthetic product side by side, highlighting the changes in red, green and orange. It then presents workers with 6 single choice questions, asking for the correctness of the generated attribute value, the readability of the new product.